1. Định nghĩa
Screaming Frog là một công cụ SEO (Search Engine Optimization) mạnh mẽ được sử dụng để thu thập dữ liệu các trang web, phân tích và kiểm tra các yếu tố SEO trên trang web. Công cụ này được phát triển bởi công ty Screaming Frog, có trụ sở tại Anh. Screaming Frog SEO Spider là sản phẩm nổi tiếng nhất của họ.
2. Màn hình làm việc
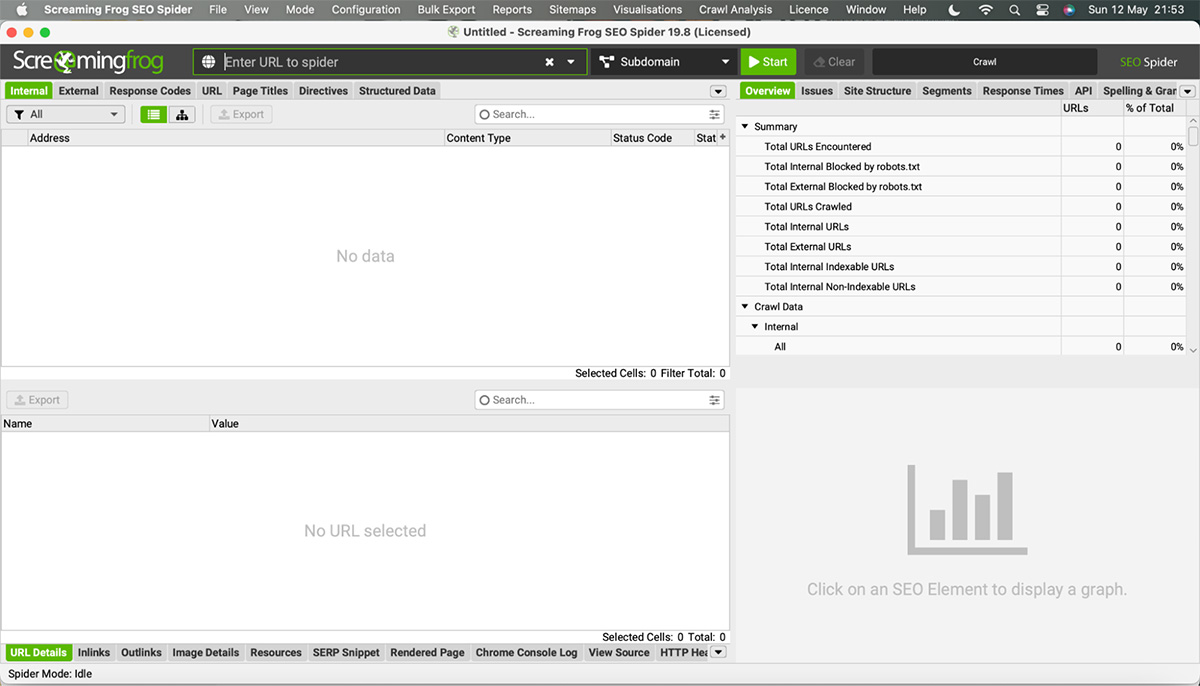
Các thành phần quan trọng:
- Ô tìm kiếm: Nhập website cần crawl
- Các Nút Start, Clear: Bắt đầu hoặc xóa dữ liệu đã crawl
- Thanh tiến độ Crawl
- Vùng dữ liệu bên góc trái trên cùng: Screaming Frog trả về dữ liệu toàn bộ Website
- Vùng dữ liệu bên phải trên cùng: Số liệu thống kê nhanh các yếu tố đã crawl
- Vùng dữ liệu bên góc trái dưới cùng: Chi tiết từng dữ liệu của từng URL
- Vùng dữ liệu bên phải dưới cùng: Biểu đồ minh hoạ dữ liệu
- Thanh điều hướng trên cùng: Cài đặt quét, xuất dữ liệu, v.v.
3 tính năng cơ bản của Screaming Frog
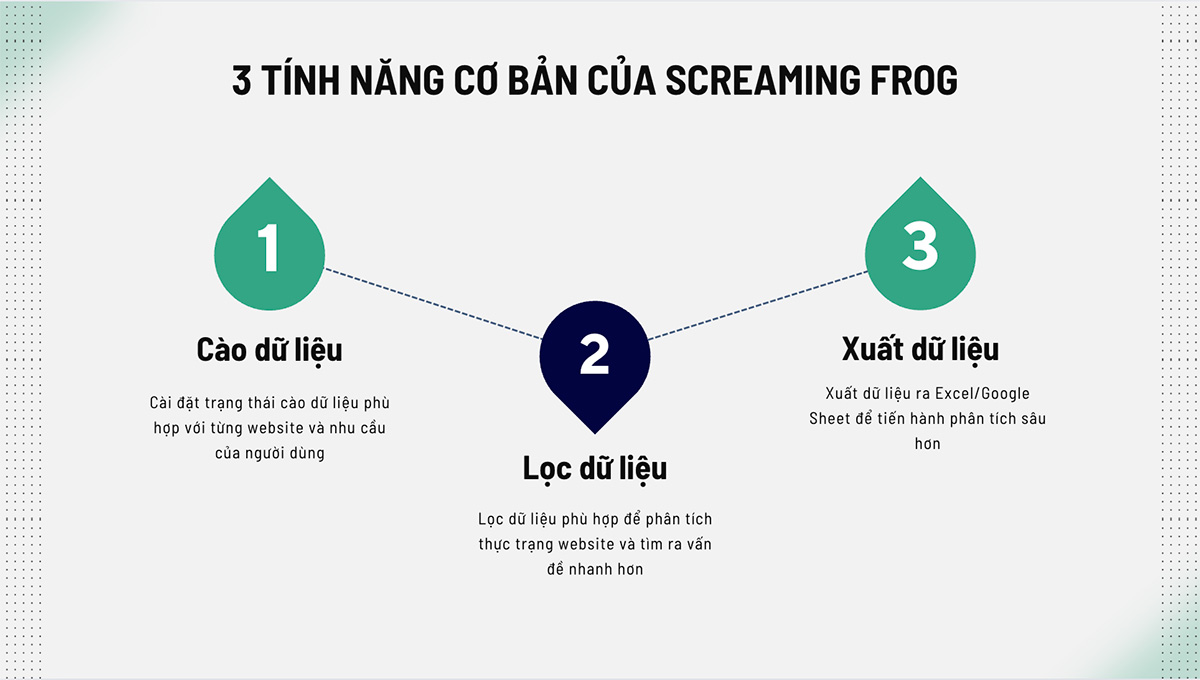
3.1. Cào dữ liệu & Định cấu hình cào dữ liệu
3.1.1. 2 trạng thái cào dữ liệu cơ bản
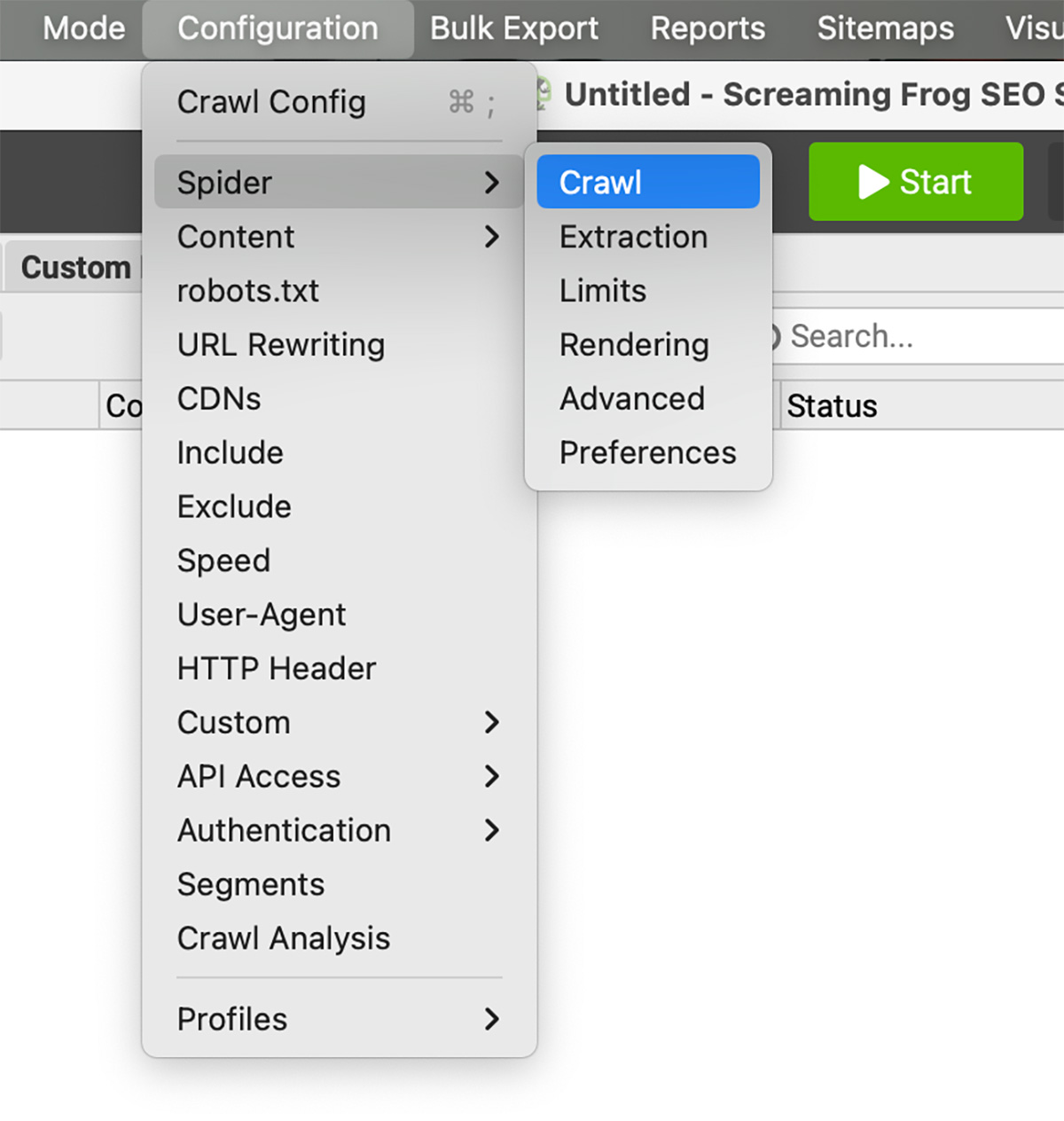
Screaming Frog cung cấp 2 trạng thái cào dữ liệu cơ bản mà bạn có thể điều chỉnh ở tab Mode của thanh điều hướng:
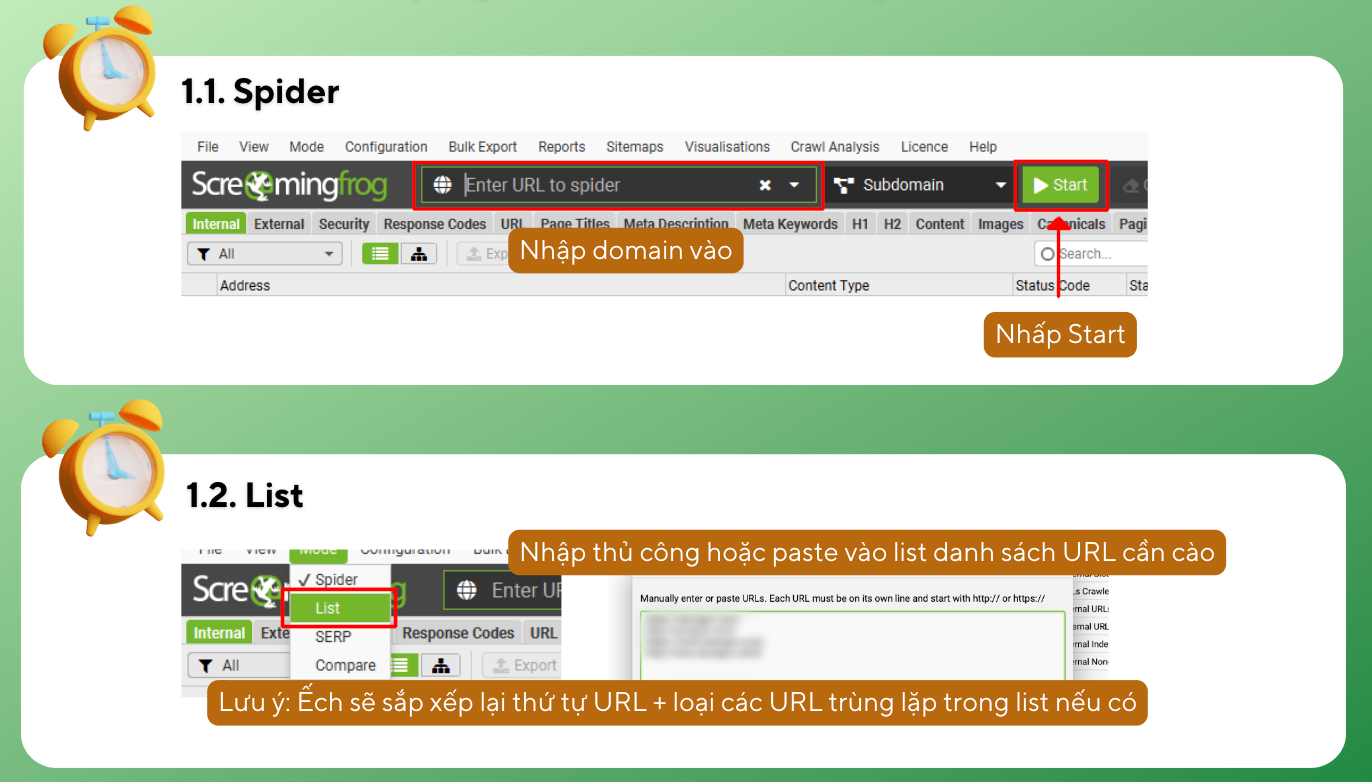
- Spider: Cào dữ liệu theo dạng domain
- List: Cào danh sách dữ liệu được nhập thủ công hoặc copy paste
Lưu ý: Với dạng list, Screaming Frog sẽ sắp xếp lại thứ tự URL + loại các URL trùng lặp trong list nếu có.
Ngoài ra, bạn có thể điều chỉnh các dạng cào dữ liệu nâng cao hơn bằng cách định cấu hình dữ liệu ở tab Configuration trên thanh điều hướng.
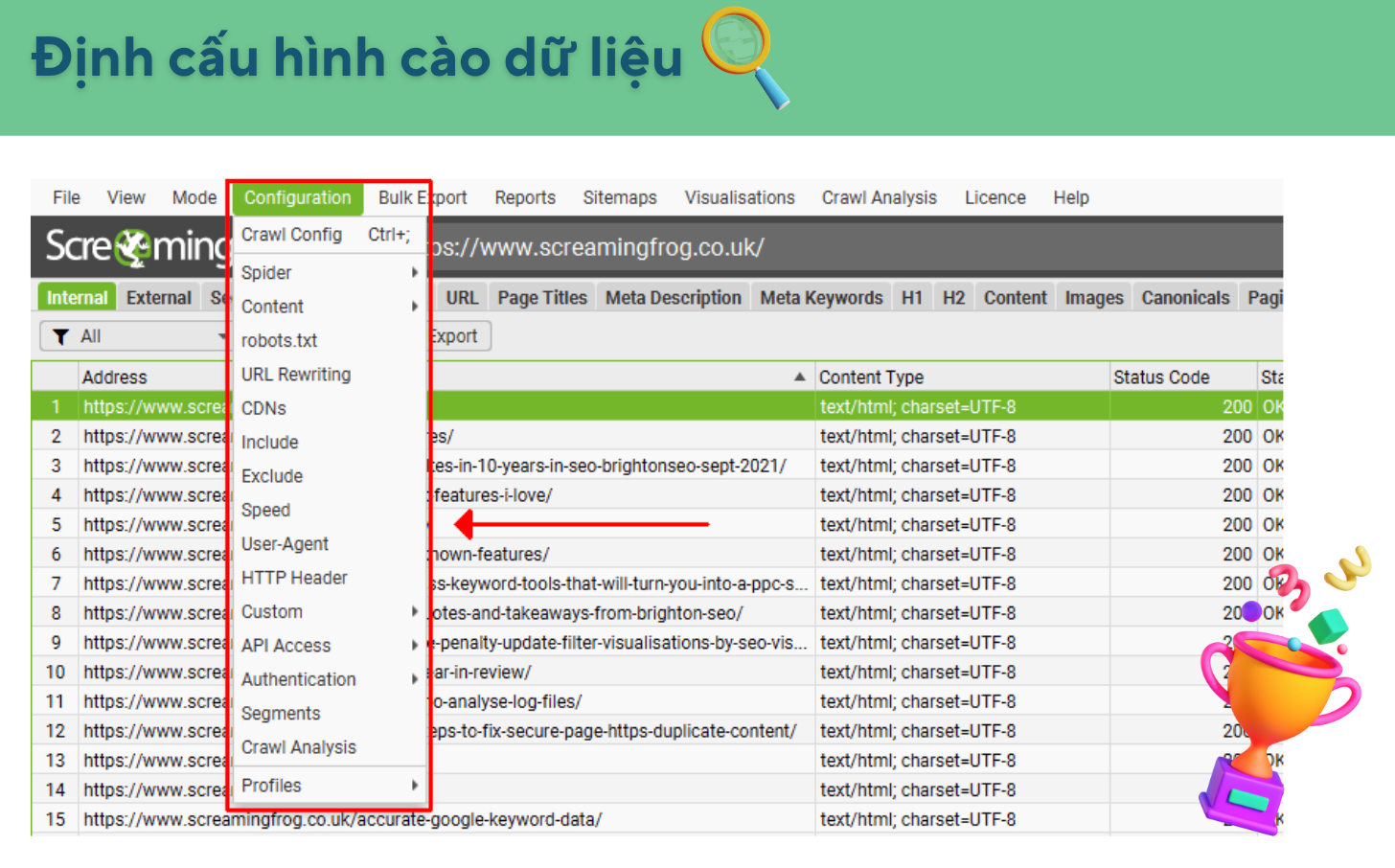
Đọc thêm về Configuration: SEO Spider Configuration – Screaming Frog
3.1.2. Định cấu hình cào dữ liệu nâng cao
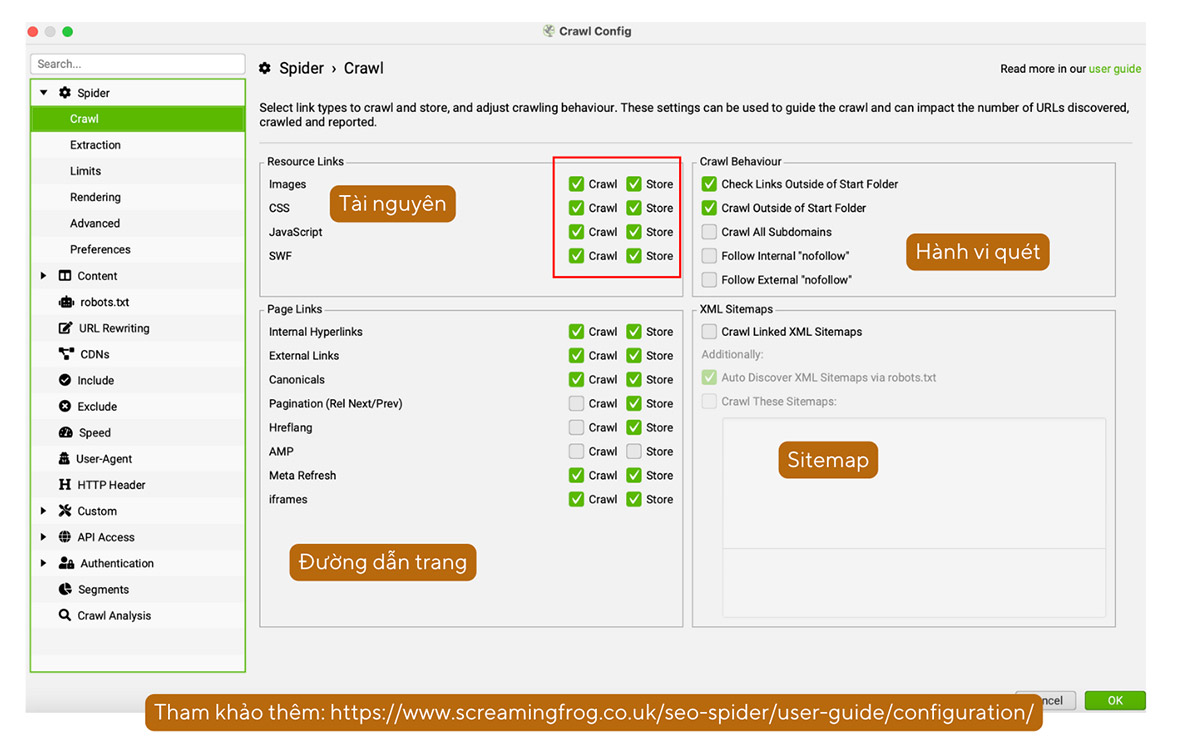
a. Tuỳ chỉnh hành vi cào của Screaming Frog: Spider > Crawl
Định cấu hình Crawl sẽ cho phép bạn tùy chỉnh các tài nguyên, hành vi quét và các loại đường dẫn mà Screaming Frog sẽ quét. Ví dụ, bỏ tick ở ô Crawl và Store của Images thì Screaming Frog sẽ không thu thập các dữ liệu liên quan đến hình ảnh trên website của bạn.
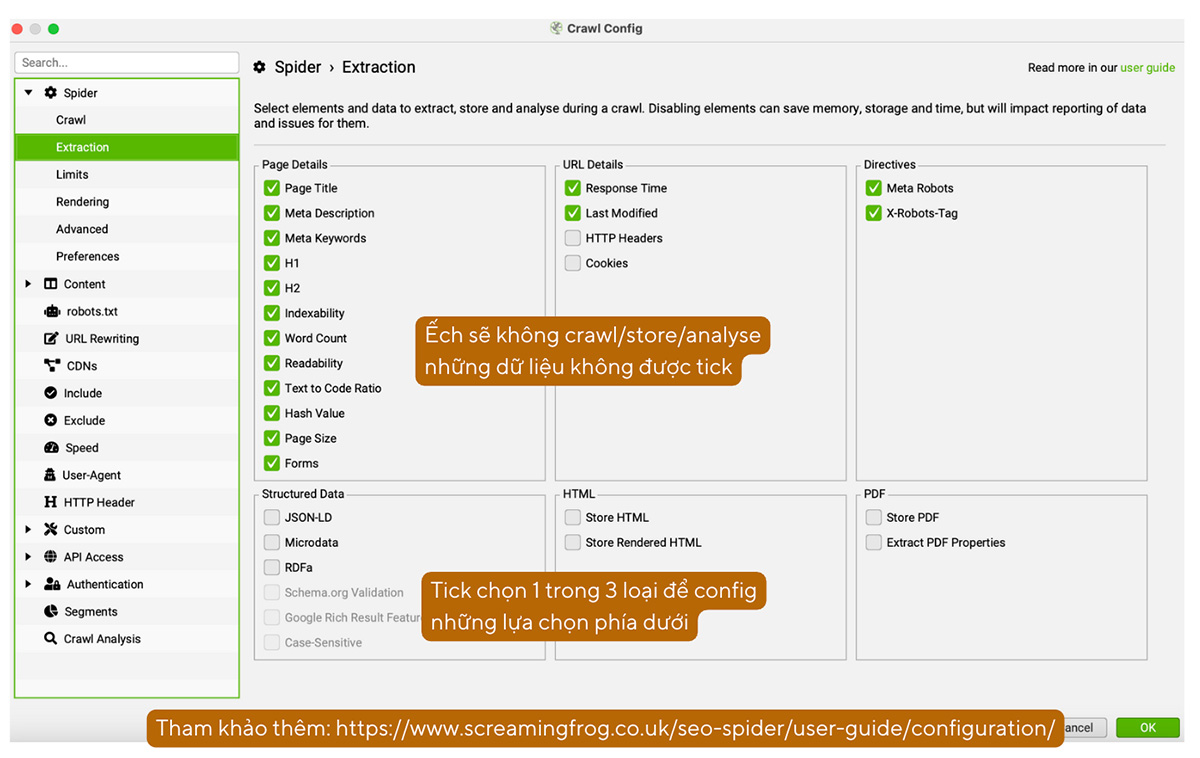
b. Tùy chỉnh dữ liệu Screaming Frog cào: Spider > Extraction
Định cấu hình ở phần Extraction sẽ cho phép bạn tùy chỉnh các dữ liệu mà Screaming Frog sẽ trích xuất, lưu trữ và phân tích trong khi cào dữ liệu.
Ví dụ: Nếu bạn chỉ cần trích xuất Page Title và Meta, bạn có thể bỏ tick ở các trường Indexicality, Word Count.
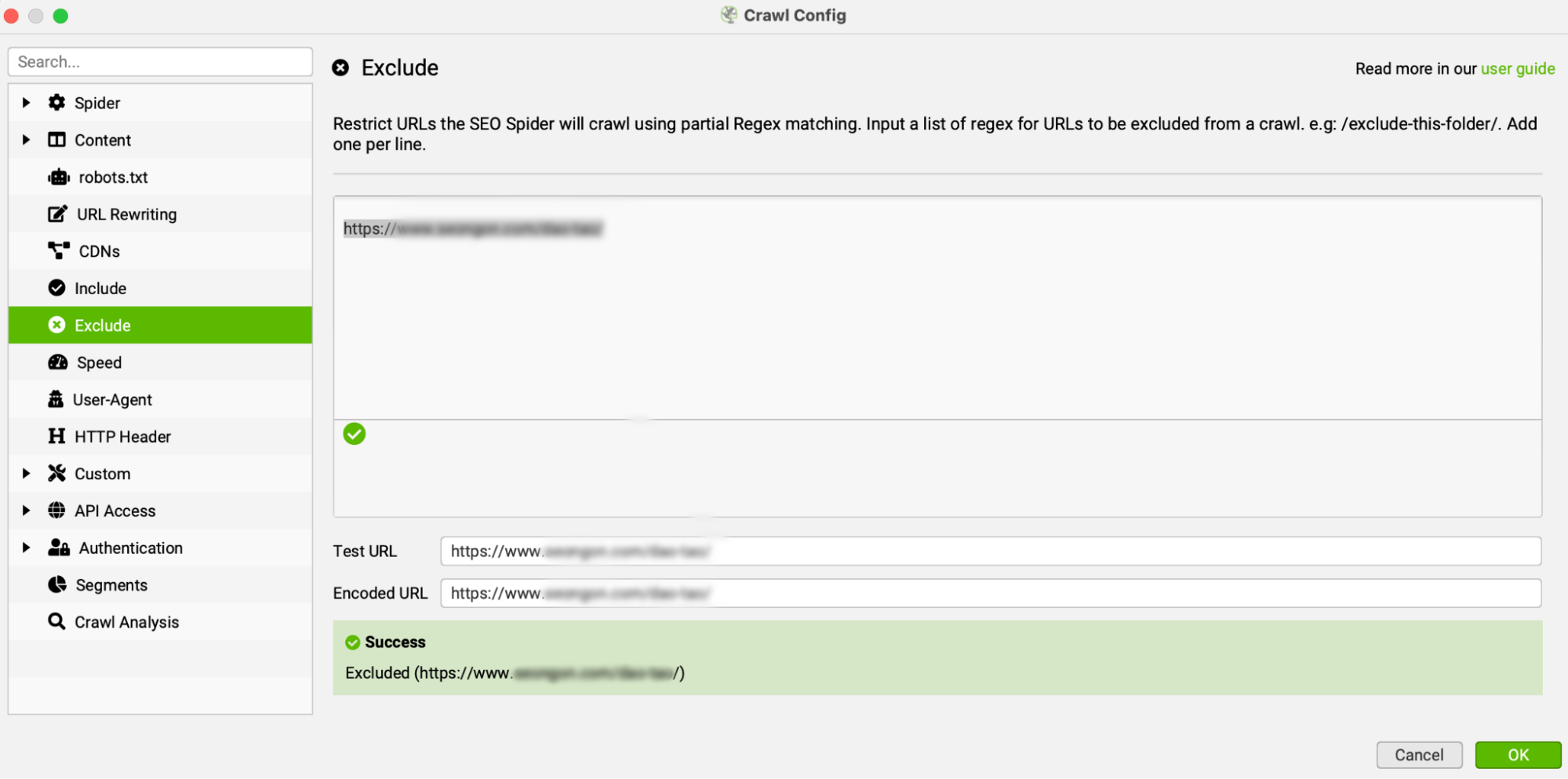
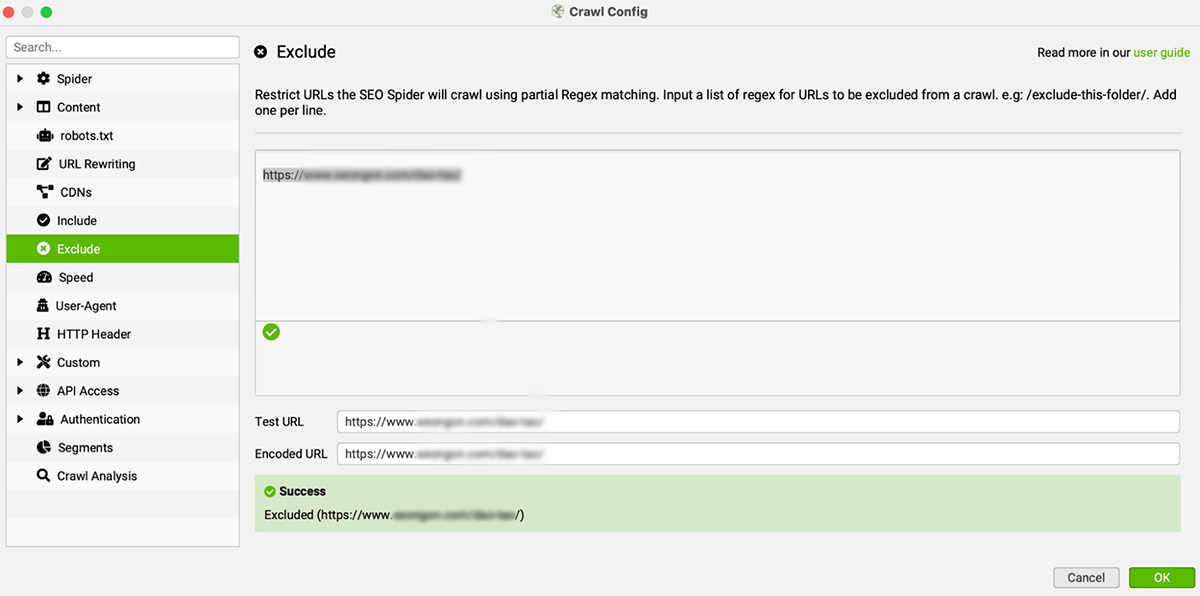
c. Tuỳ chỉnh các URL mà Screaming Frog cào: Include/Exclude
Bạn có thể tìm thấy tính năng Include/Exclude trong phần Content. Bạn có thể nhập một chuỗi các URL mà bạn không muốn Screaming Frog cần phải cào theo cú pháp /url/
Ví dụ: Khi cào SEONGON, bạn muốn cào tất cả các URL trừ các URL thuộc phần đào tạo và phần tuyển dụng. Bạn chỉ cần nhập URL: https://www.seongon.com/dao-tao/ vào ô trống trong phần Exclude.
Tính năng này có thể áp dụng khi bạn muốn quét website nặng hoặc siêu nặng do có nhiều bộ lọc/đa ngôn ngữ, v.v.
Lưu ý: Chức năng “exclude” (loại trừ) cho phép bạn loại trừ các URL khỏi quá trình thu thập dữ liệu bằng cách sử dụng khớp một phần với regex. Một URL khớp với “exclude” sẽ không được thu thập dữ liệu (không chỉ là ‘ẩn’ trong giao diện). Điều này có nghĩa là các URL khác không khớp với “exclude”, nhưng chỉ có thể truy cập từ một URL bị exclude, cũng sẽ không được tìm thấy trong quá trình thu thập dữ liệu.
Danh sách “exclude” được áp dụng cho các URL mới được phát hiện trong quá trình thu thập dữ liệu. Danh sách “exclude” này không áp dụng cho các URL ban đầu được cung cấp trong chế độ crawl hoặc list mode.
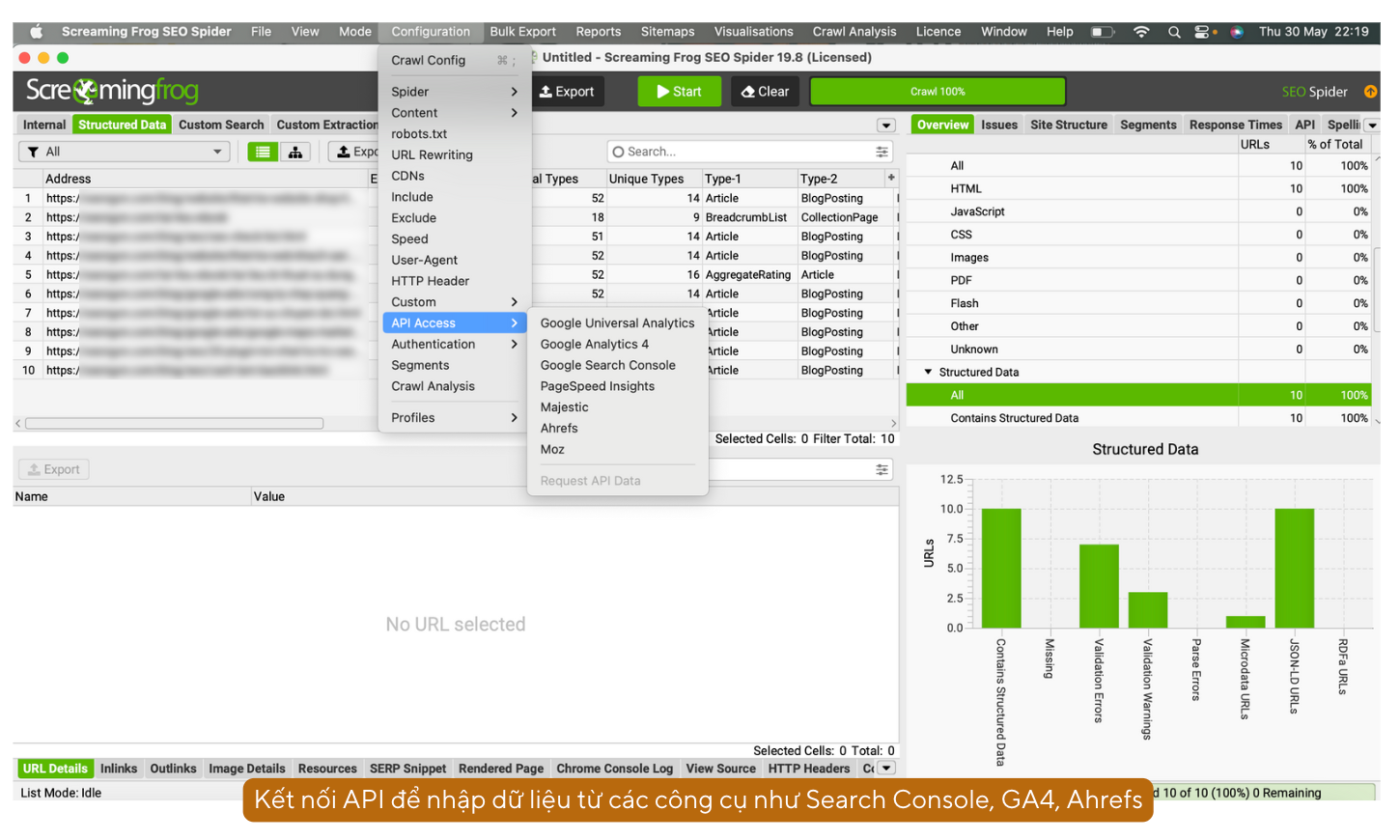
d. Tùy chỉnh nguồn cào dữ liệu: Spider > API Access
Chức năng API Access sẽ cho phép bạn kết nối Screaming Frog với các công cụ như GA4, Google Search Console, PageSpeed Insights, v.v. để lấy dữ liệu trực tiếp.
Ví dụ: Kết hợp Screaming Frog với Google Search Console sẽ cho phép bạn trích xuất URL Clicks, Impressions, v.v. của một URL bất kỳ trên site.
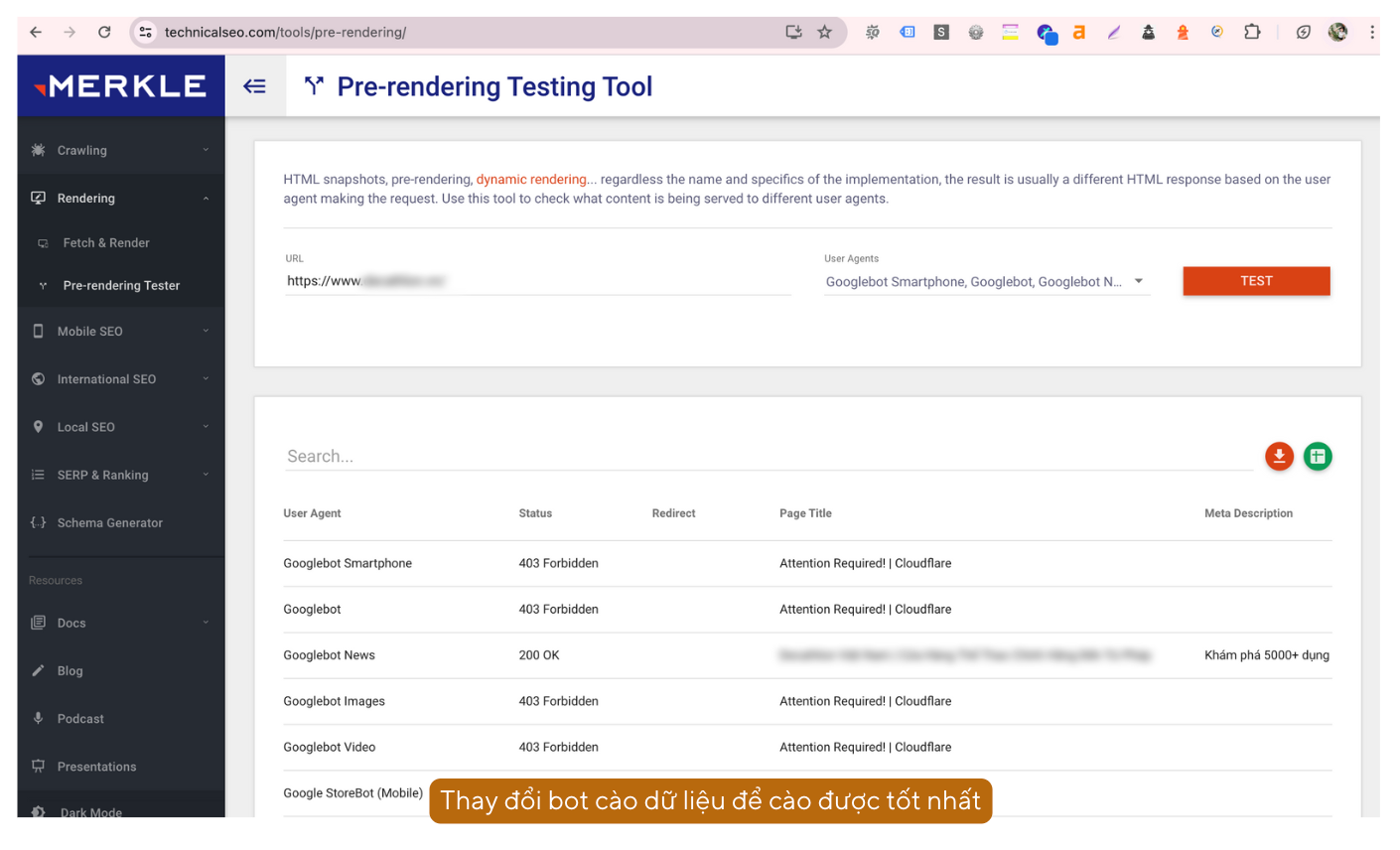
e. Tuỳ chỉnh bot cào dữ liệu: Spider > User-Agent
Chức năng nâng cao này cho phép bạn thay đổi bot cào dữ liệu để biết được các loại bot đang thu thập được các dữ liệu gì từ website của bạn.
Bạn có thể sử dụng công cụ technicalseo: https://technicalseo.com/tools/pre-rendering/ để xem trước danh sách các loại bot đang được cào website của bạn, sau đó vào Screaming Frog để tùy chỉnh cho phù hợp.

f. Tùy chỉnh cơ sở trích xuất dữ liệu: Spider > Rendering
Định cấu hình Rendering cho phép bạn cào dữ liệu của các website Java đảm bảo không bị sót link. Lưu ý rằng cào Java sẽ chậm và dữ liệu lớn, có thể gây lag máy.
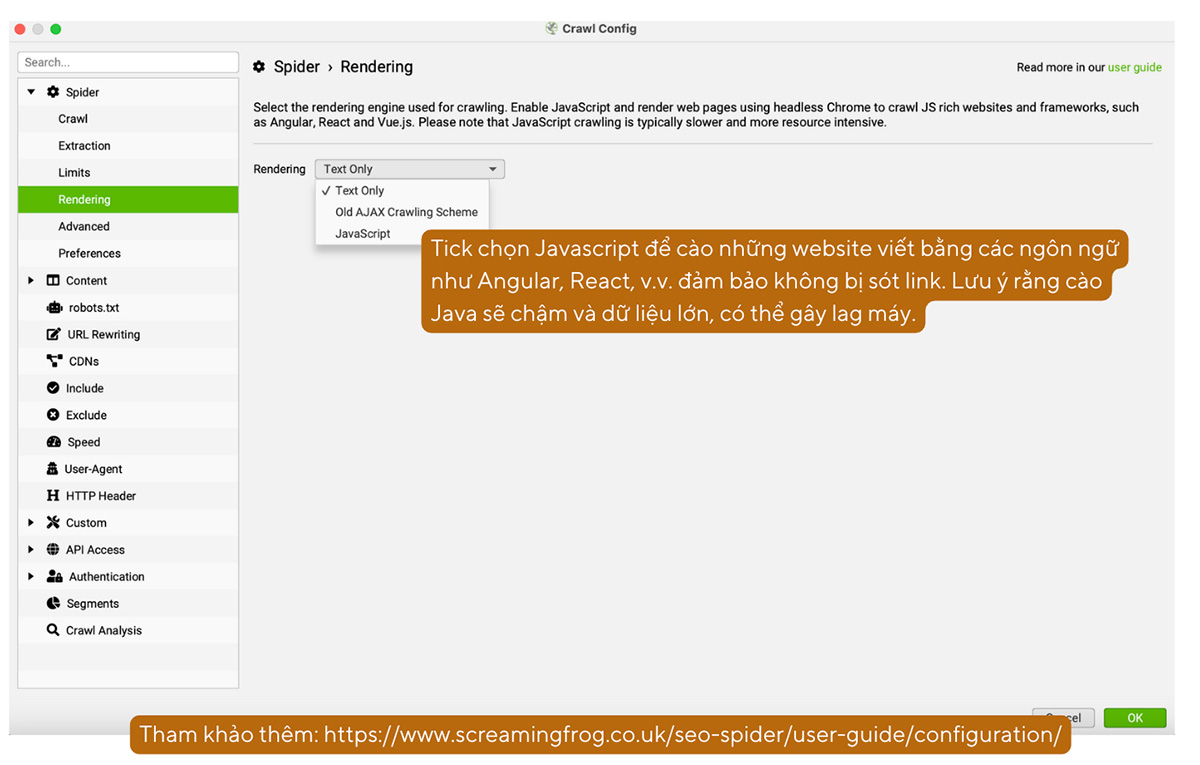
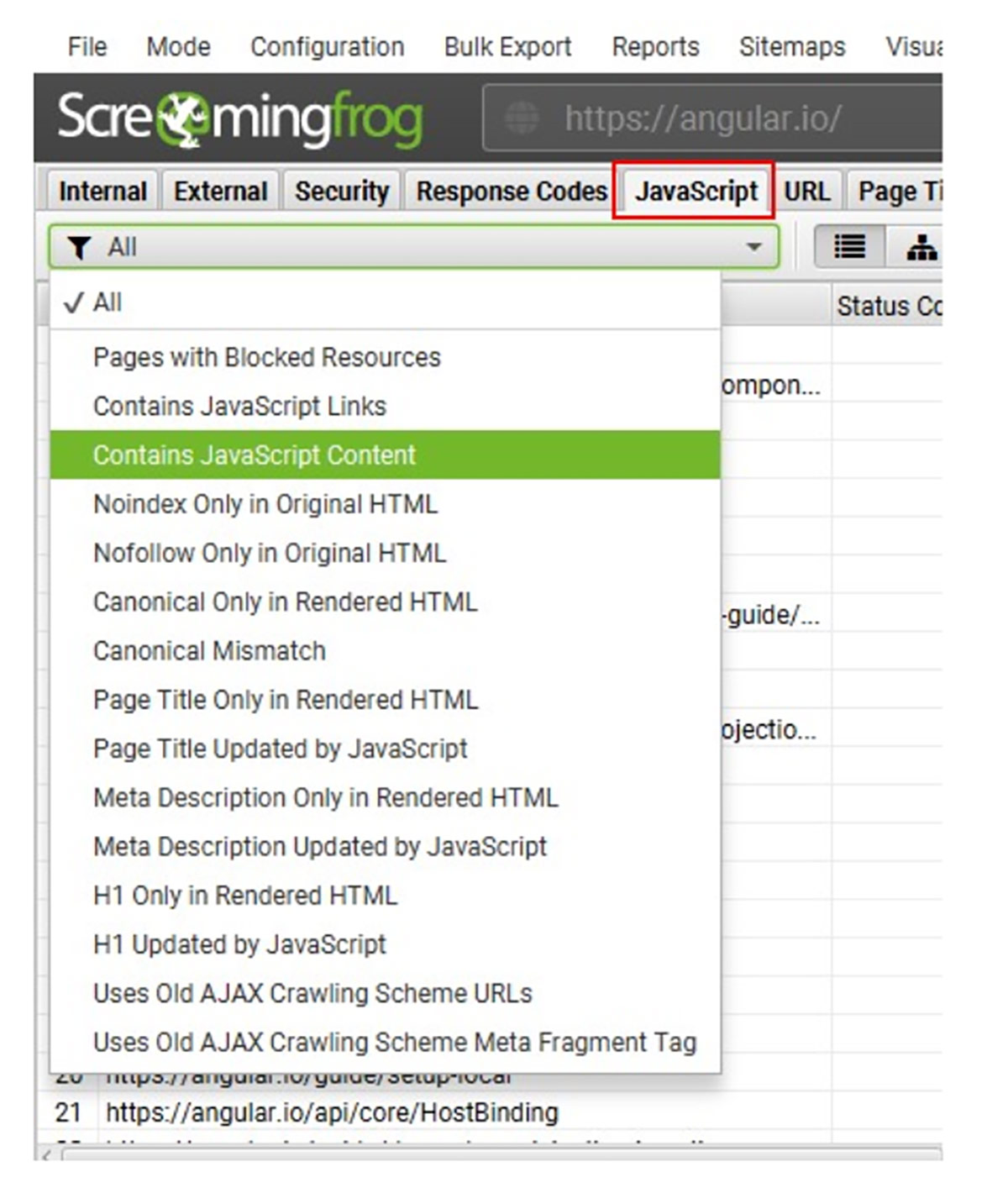
Khi cào website bằng Java, Screaming Frog sẽ list ra các vấn đề cần sửa đối với website Java như:
- Pages with Blocked Resources: 1 số tài nguyên như ảnh, Java, CSS có thể bị chặn bởi tệp robots.txt
- Contains JavaScript Links/Content: Trang chứa tài nguyên chỉ đọc được sau khi render Java.
- Noindex/Nofollow/Canonical Only in Original HTML: Trang chứa thẻ noindex trong Raw HTML (chưa render) sẽ bị Googlebot bỏ qua và không render.
- Canonical Mismatch: Thẻ canonical ở HTML trước và sau khi render không khớp.
- Page Title/Meta/H1: Các trang có title, meta, H1 khác nhau trước và sau khi render.
- Old AJAX: Các trang vẫn sử dụng crawling schema cũ mà Google đã khai tử từ 2015.
Để làm việc với web Java thì nên đọc tài liệu này: https://developers.google.com/search/docs/crawling-indexing/javascript/javascript-seo-basics?hl=vi
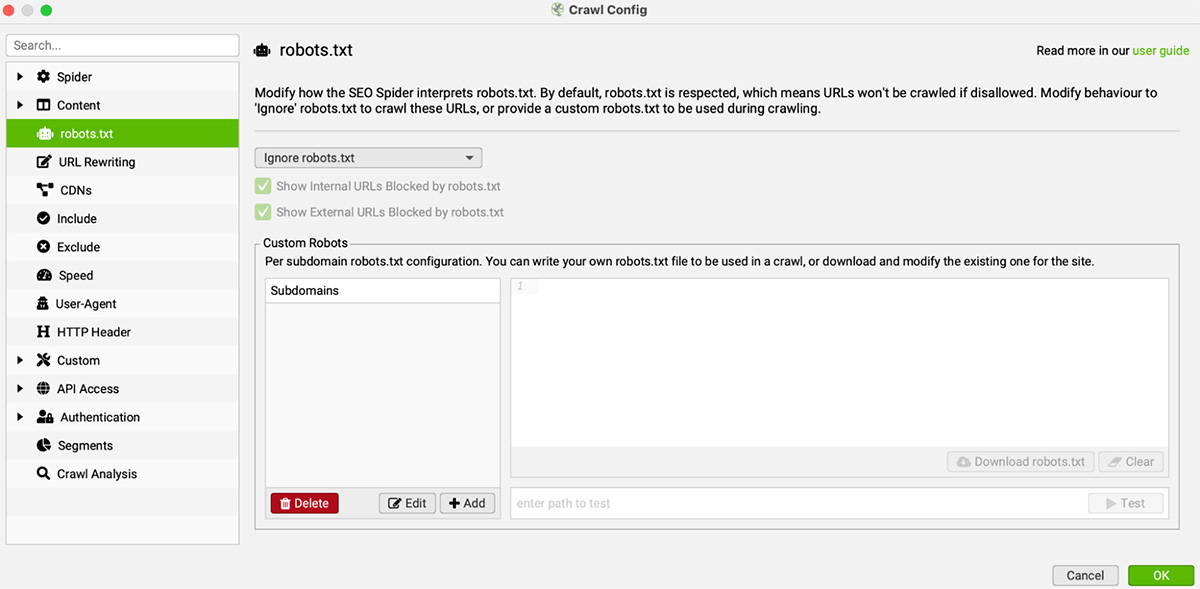
g. Tuỳ chỉnh tệp robots.txt: Spider > Robots.txt
Tính năng này sẽ cho phép Screaming Frog bỏ qua tệp robots.txt và truy cập các URL bị chặn trong đó. Đây là case thường gặp trong website demo nếu web demo của bạn đang chặn index bằng robots.txt.
Để bỏ qua robots.txt, truy cập Spider > Robots.txt > Chọn Ignore robots.txt
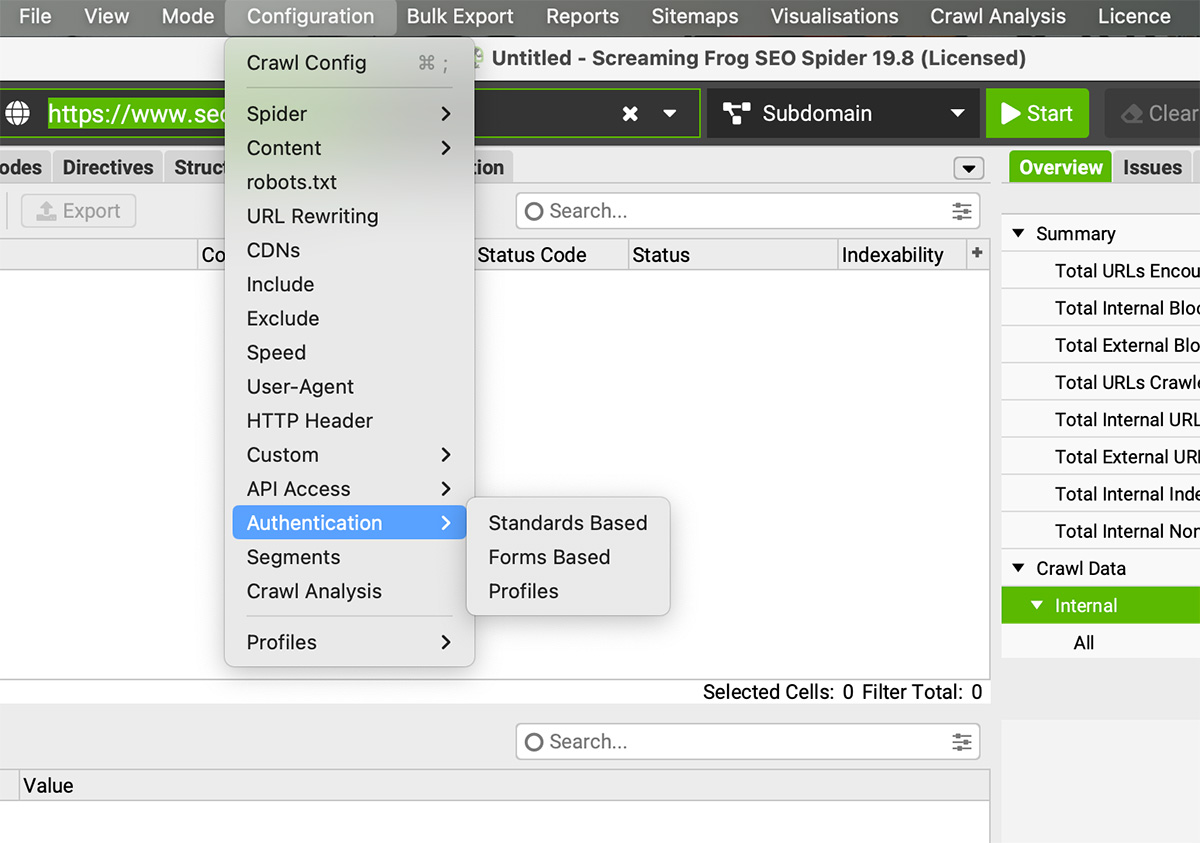
h. Tuỳ chỉnh xác thực dữ liệu: Spider > Authentication
Đối với 1 số website demo bị chặn xác thực bằng username + password, bạn có thể cung cấp các thông tin này để Screaming Frog có thể quét được website bằng cách truy cập Spider > Authentication > Standard Based/Forms Based.
Lưu ý khi cào website demo:
- Tốc độ: Website demo thường chịu tải kém hơn website thường, nên có thể bạn cần giảm tốc độ cào của Ếch bằng cách truy cập Spider > Speed.
- Nofollow: Trong phần Spider > Crawl, bạn nên tick chọn ô Follow Internal ‘nofollow’ để không bị bỏ sót link.
- Noindex: Các URL noindex có thể sẽ không được phân tích các lỗi như duplicate, missing titles, v.v. Do đó bạn nên truy cập Spider > Advanced > bỏ tick ở ô ‘Ignore Non-Indexable URLs for Issues’ để kiểm tra được hết.
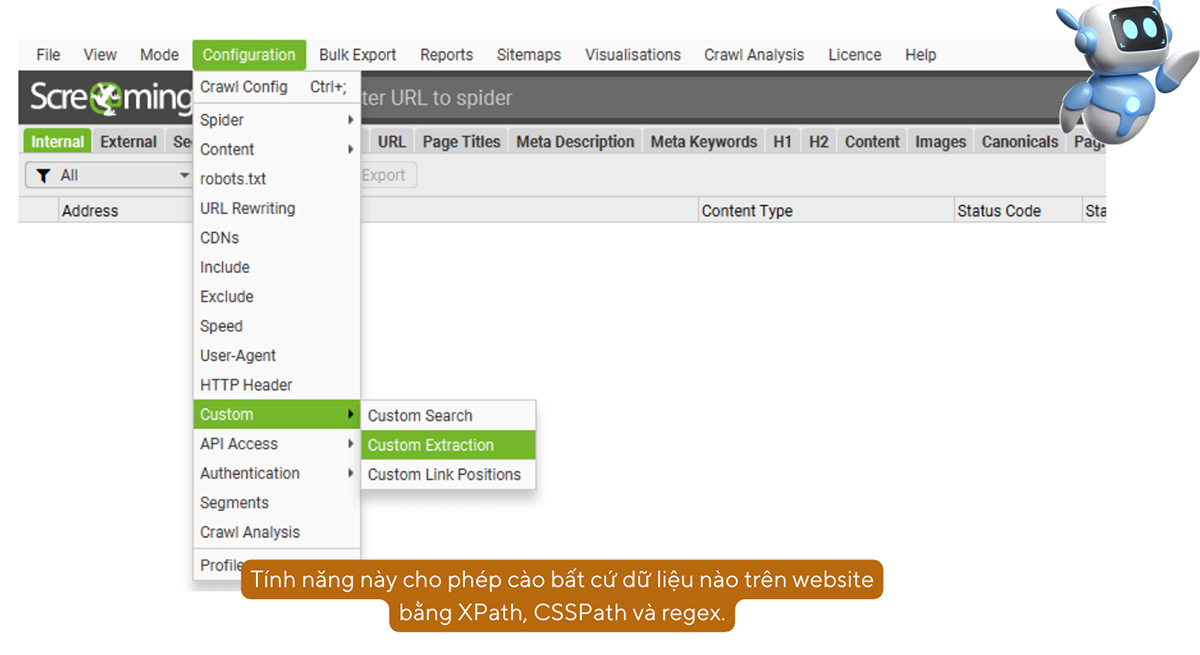
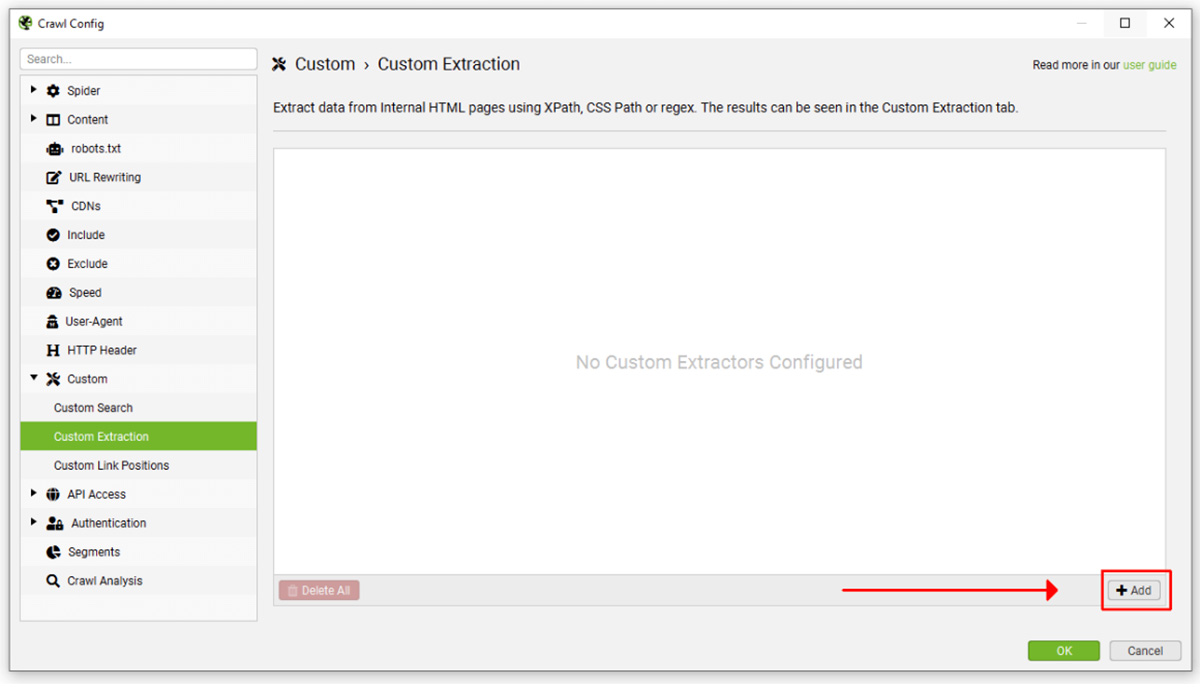
i. Trích xuất dữ liệu tùy ý: Custom Extraction
Tính năng Custom Extraction trong Screaming Frog cho phép người dùng tùy chỉnh và trích xuất các thông tin cụ thể từ các trang web mà họ muốn thu thập. Đây là một tính năng mạnh mẽ giúp bạn lấy được các dữ liệu không phải là các yếu tố SEO chuẩn mà bạn cần cho phân tích hoặc báo cáo. Dưới đây là một số khả năng của tính năng Custom Extraction:
- Trích xuất dữ liệu từ các thẻ HTML: Bạn có thể tùy chỉnh để trích xuất dữ liệu từ các thẻ HTML cụ thể như <div>, <span>, <meta>, <a> và nhiều thẻ khác bằng cách sử dụng XPath hoặc CSS Path.
- Trích xuất thuộc tính của thẻ: Ngoài việc trích xuất nội dung bên trong thẻ, bạn cũng có thể trích xuất các thuộc tính của thẻ như href, src, alt, title, v.v.
- Trích xuất dữ liệu JSON-LD: Screaming Frog cho phép trích xuất và phân tích dữ liệu JSON-LD, một định dạng dữ liệu có cấu trúc được sử dụng rộng rãi trên web.
- Trích xuất dữ liệu từ các trang động: Với khả năng render JavaScript, bạn có thể trích xuất dữ liệu từ các trang web có sử dụng JavaScript để tải nội dung.
- Tạo các quy tắc trích xuất riêng: Bạn có thể thiết lập các quy tắc trích xuất riêng cho từng loại dữ liệu mà bạn cần, giúp bạn lấy được chính xác những thông tin cần thiết.
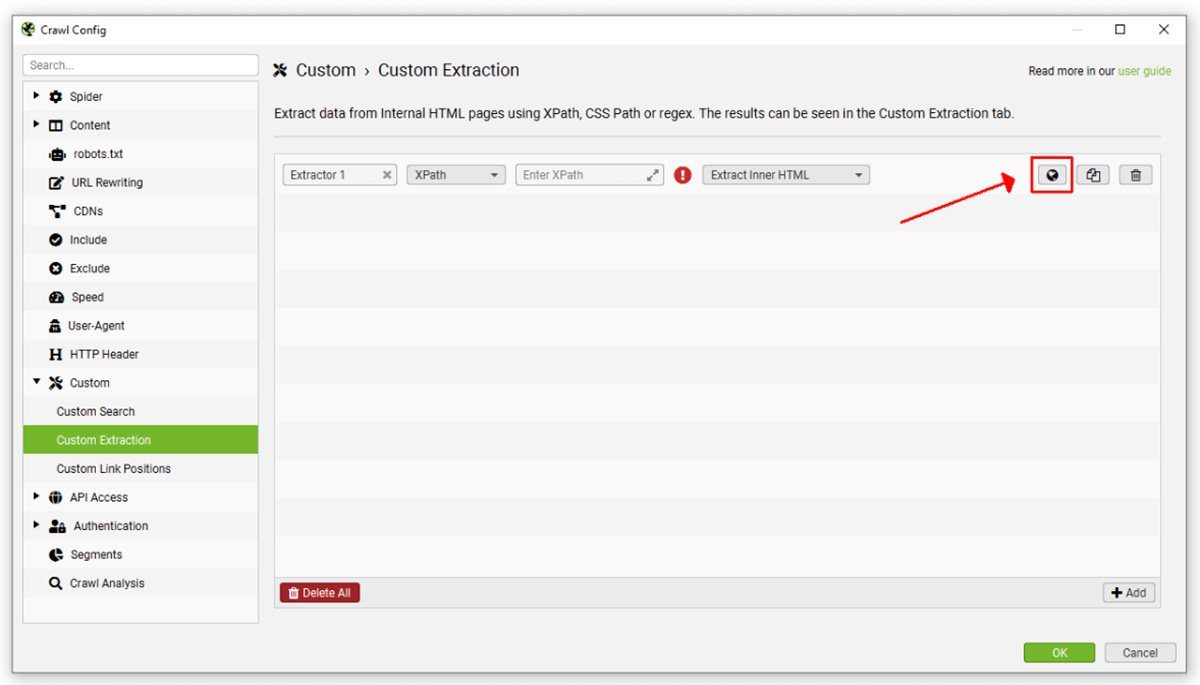
Để lấy Xpath hay CSSPath nhanh, bạn có thể click vào nút biểu tượng Web để truy cập vào trang web và lấy thông tin ngay trong Screaming Frog.
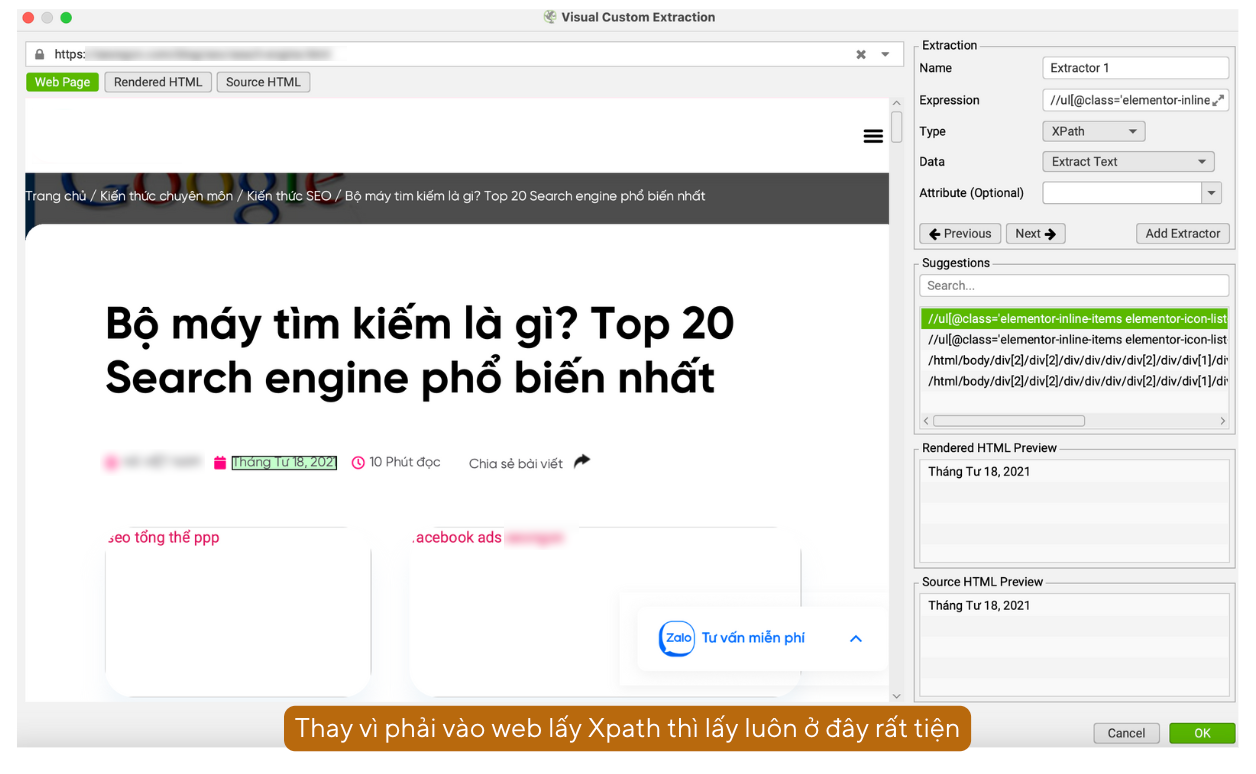
Xem thêm: https://www.screamingfrog.co.uk/seo-spider/tutorials/web-scraping/
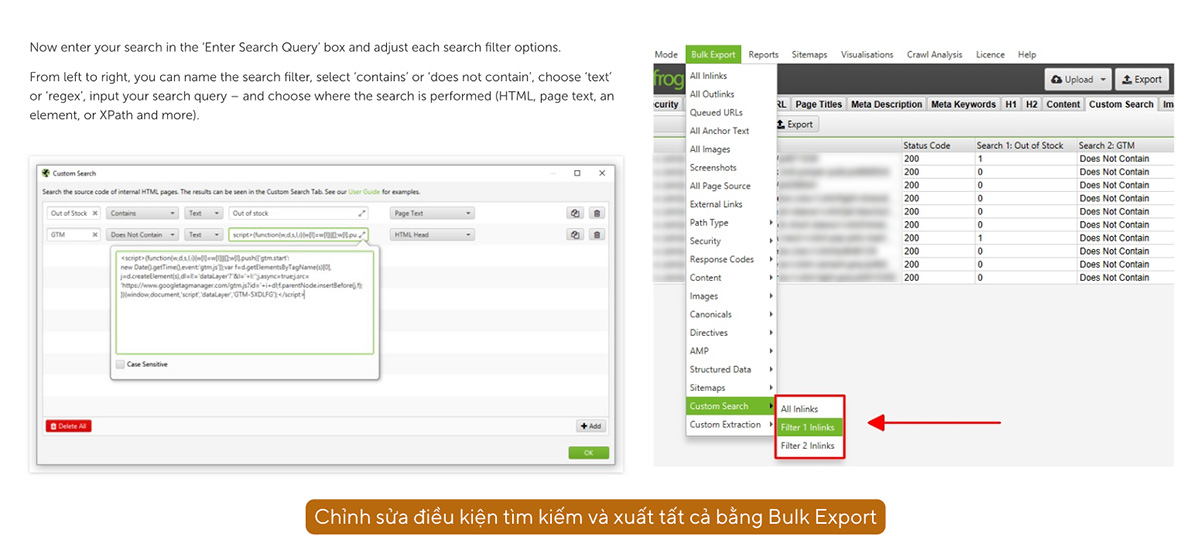
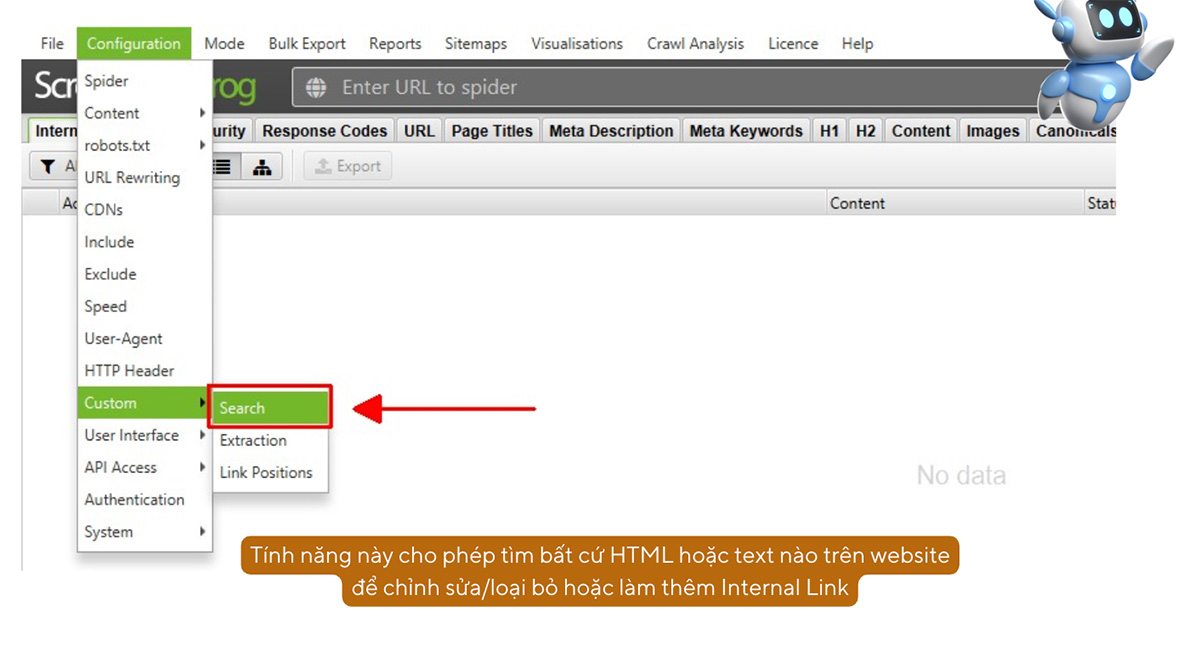
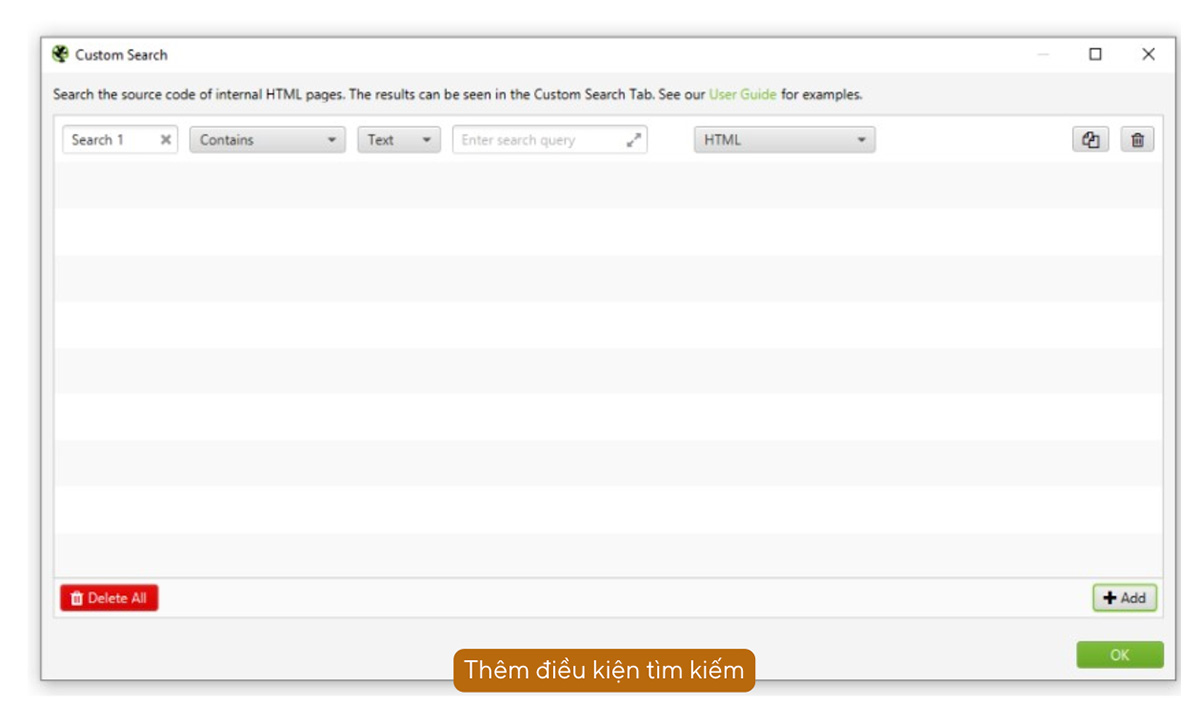
j. Tìm kiếm dữ liệu trong HTML: Custom Search
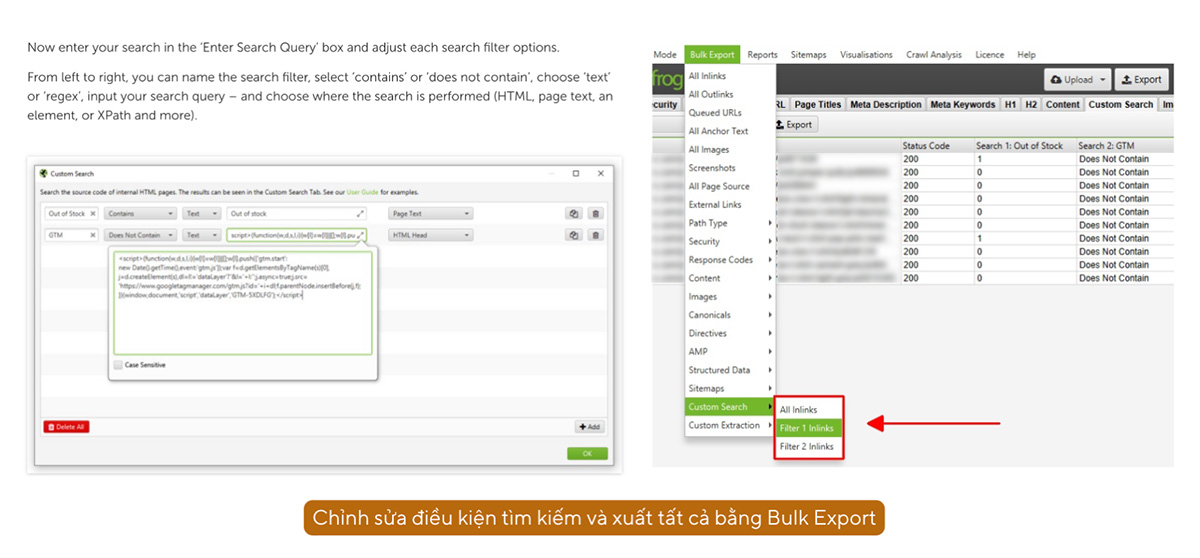
Custom Search cho phép bạn tìm kiếm các mẫu (pattern) cụ thể trong nội dung HTML của các trang web mà bạn thu thập dữ liệu. Bạn có thể sử dụng tính năng này để xác định sự xuất hiện của một số văn bản, mã, hoặc các yếu tố khác mà bạn quan tâm. Dưới đây là một số điểm nổi bật của Custom Search:
- Tìm kiếm theo từ khóa hoặc chuỗi văn bản: Bạn có thể nhập các từ khóa hoặc chuỗi văn bản cụ thể mà bạn muốn tìm trong nội dung trang web.
- Sử dụng biểu thức chính quy (Regular Expressions): Hỗ trợ sử dụng regex để tìm kiếm các mẫu phức tạp hơn.
- Tìm kiếm trong nhiều phần của trang: Bạn có thể chỉ định tìm kiếm trong các phần khác nhau của trang như URL, tiêu đề trang, meta description, nội dung thẻ H1, H2, nội dung HTML, v.v.
- Báo cáo sự xuất hiện: Tính năng này giúp bạn biết liệu các từ khóa hoặc mẫu đã cho có xuất hiện trên trang hay không và nếu có, chúng xuất hiện bao nhiêu lần.

3.2. Tương tác với dữ liệu
3.2.1. Các vùng dữ liệu có thể tương tác
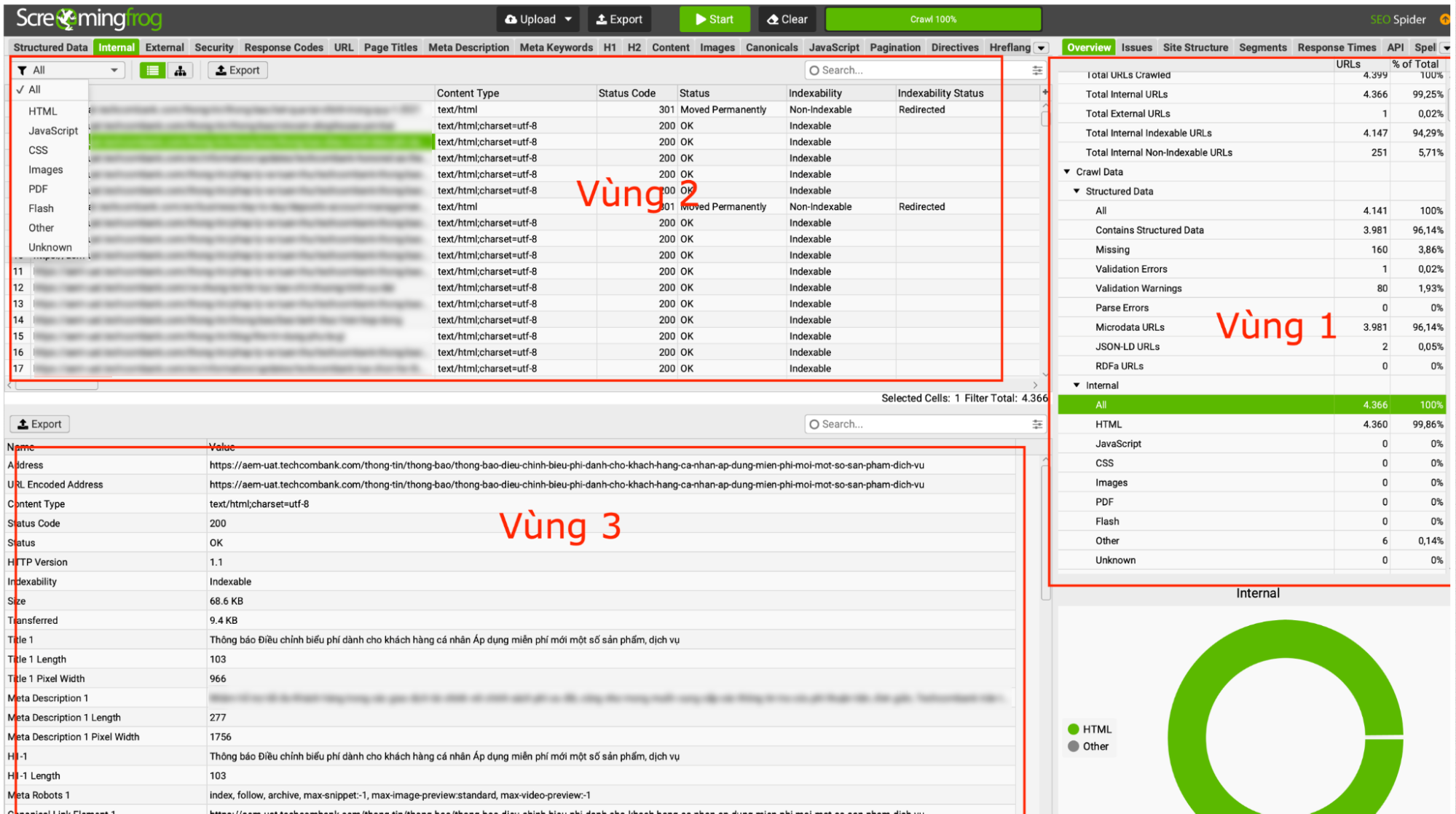
Trong ảnh là 3 vùng dữ liệu mà người dùng có thể tương tác với Screaming Frog.
- Vùng 1: Xem nhanh tổng quan các vùng dữ liệu
- Vùng 2: Bảng dữ liệu tổng, cho phép người dùng tương tác với từng trường dữ liệu lớn
- Vùng 3: Bảng dữ liệu chi tiết, cho phép người dùng tương tác với từng nhóm dữ liệu
3.2.2. Các dữ liệu có thể tương tác
Dưới đây là các dữ liệu mà bạn có thể tương tác trong Screaming Frog:
- Structured Data: Dữ liệu có cấu trúc được sử dụng để cung cấp ngữ cảnh về nội dung trang web cho các công cụ tìm kiếm.
- Internal: Các liên kết nội bộ trong trang web.
- External: Các liên kết dẫn đến các trang web bên ngoài.
- Security: Thông tin về bảo mật của trang web, như việc sử dụng HTTPS.
- Response Codes: Mã phản hồi HTTP từ máy chủ (như 200, 404).
- URL: Địa chỉ của trang web.
- Page Titles: Tiêu đề trang được hiển thị trên thanh tiêu đề của trình duyệt.
- Meta Description: Mô tả ngắn gọn về nội dung trang web, hiển thị trong kết quả tìm kiếm.
- Meta Keywords: Từ khóa meta cũ dùng để xác định chủ đề trang.
- H1: Thẻ tiêu đề chính của trang.
- H2: Thẻ tiêu đề phụ.
- Content: Nội dung chính của trang.
- Images: Hình ảnh được sử dụng trên trang.
- Canonicals: Thẻ canonical để xác định URL chuẩn cho nội dung trùng lặp.
- JavaScript: Mã JavaScript được sử dụng trên trang.
- Pagination: Thông tin về việc phân trang.
- Directives: Các chỉ thị như noindex, nofollow.
- Hreflang: Thẻ xác định ngôn ngữ và khu vực của trang.
- Links: Các liên kết trên trang.
- AMP: Trang di động tăng tốc.
- Sitemaps: Sơ đồ trang web giúp công cụ tìm kiếm hiểu cấu trúc trang.
- PageSpeed: Tốc độ tải trang.
- Custom Search: Tìm kiếm tùy chỉnh các mẫu hoặc từ khóa cụ thể.
- Custom Extraction: Trích xuất dữ liệu tùy chỉnh từ trang.
- Analytics: Dữ liệu phân tích về lưu lượng truy cập.
- Search Console: Công cụ quản trị trang web của Google.
- Validation: Kiểm tra tính hợp lệ của mã HTML.
- Link Metrics: Các số liệu về liên kết.
3.2.3. Các cách thức có thể tương tác
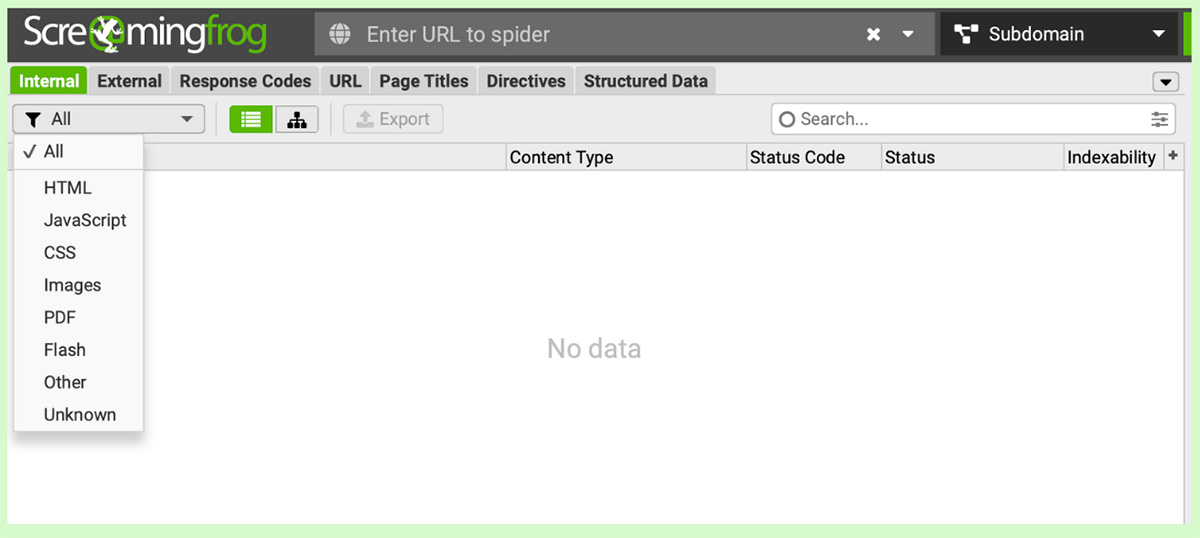
Lọc dữ liệu cơ bản và nâng cao
Đối với dữ liệu trong Screaming Frog, bạn có thể lọc bằng các cách dưới đây:
- Sử dụng thanh tìm kiếm để lọc cơ bản
- Click vào biểu tượng Lọc để lọc các loại Content (html, CSS, Images, v.v.)
- Lọc nâng cao cho phép bạn lọc theo từng tab dữ liệu và truy vấn
Tương tác dữ liệu nâng cao
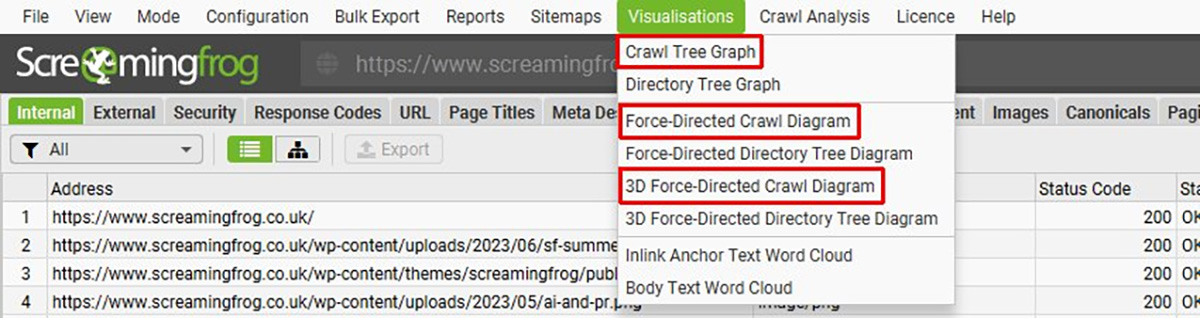
i. Visualization
Trong Screaming Frog, tính năng “visualization” giúp bạn trực quan hóa cấu trúc của trang web của bạn. Có hai loại chính của visualization:
- Crawl Visualization: Cung cấp một cái nhìn tổng quan về cách các trang trên trang web của bạn được liên kết với nhau. Điều này giúp bạn hiểu cách các liên kết nội bộ được phân bổ và có thể dễ dàng nhận diện các vấn đề về cấu trúc trang web như các trang bị cô lập hoặc các chuỗi liên kết dài.
- Site Visualization: Cung cấp một sơ đồ hình cây hoặc sơ đồ mạng của trang web của bạn. Bạn có thể thấy cấu trúc của trang web dưới dạng đồ thị, giúp dễ dàng nhận diện các mô hình liên kết, các khu vực trang web có thể cần được tối ưu hóa, và các trang quan trọng trong trang web của bạn.
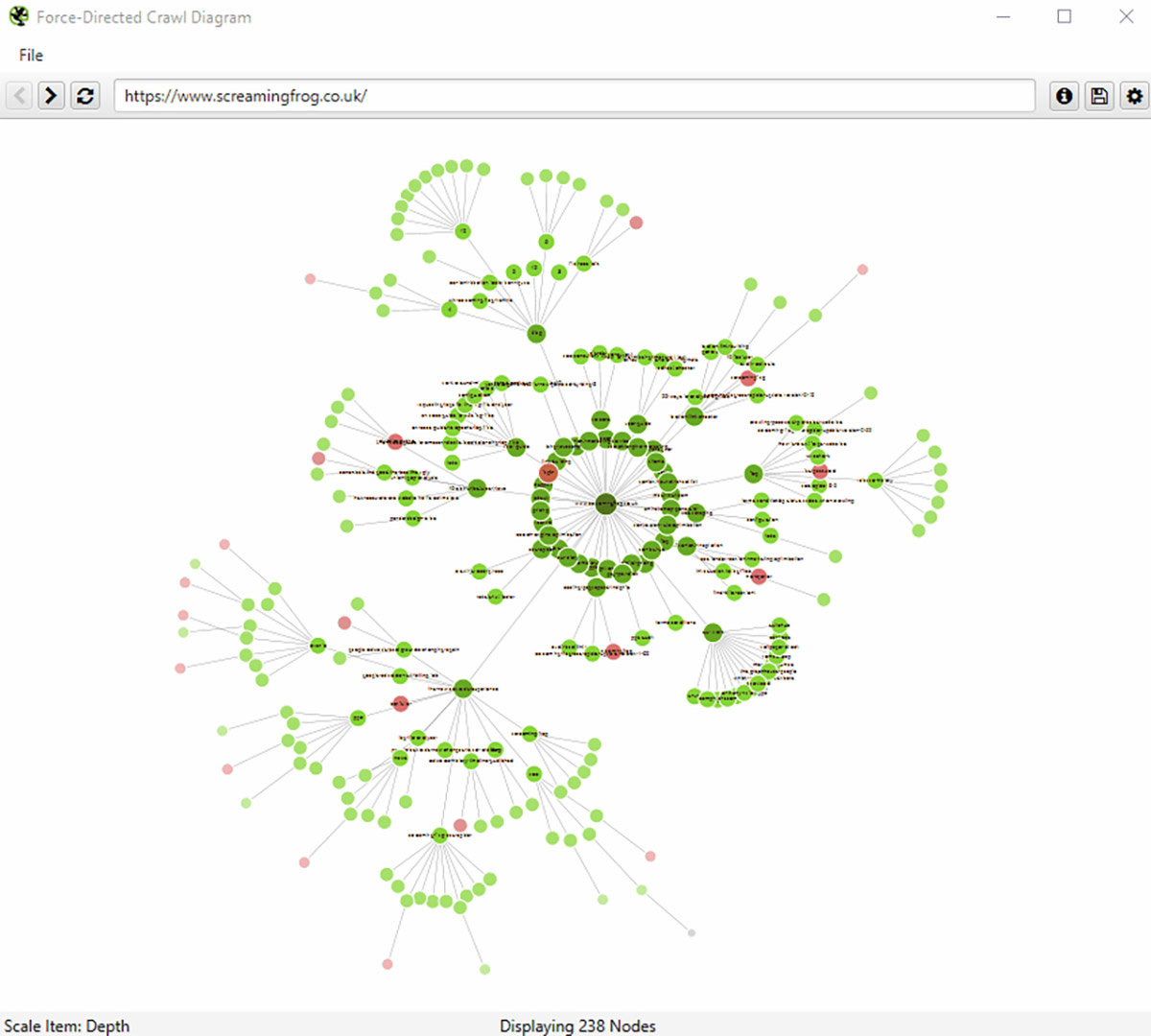
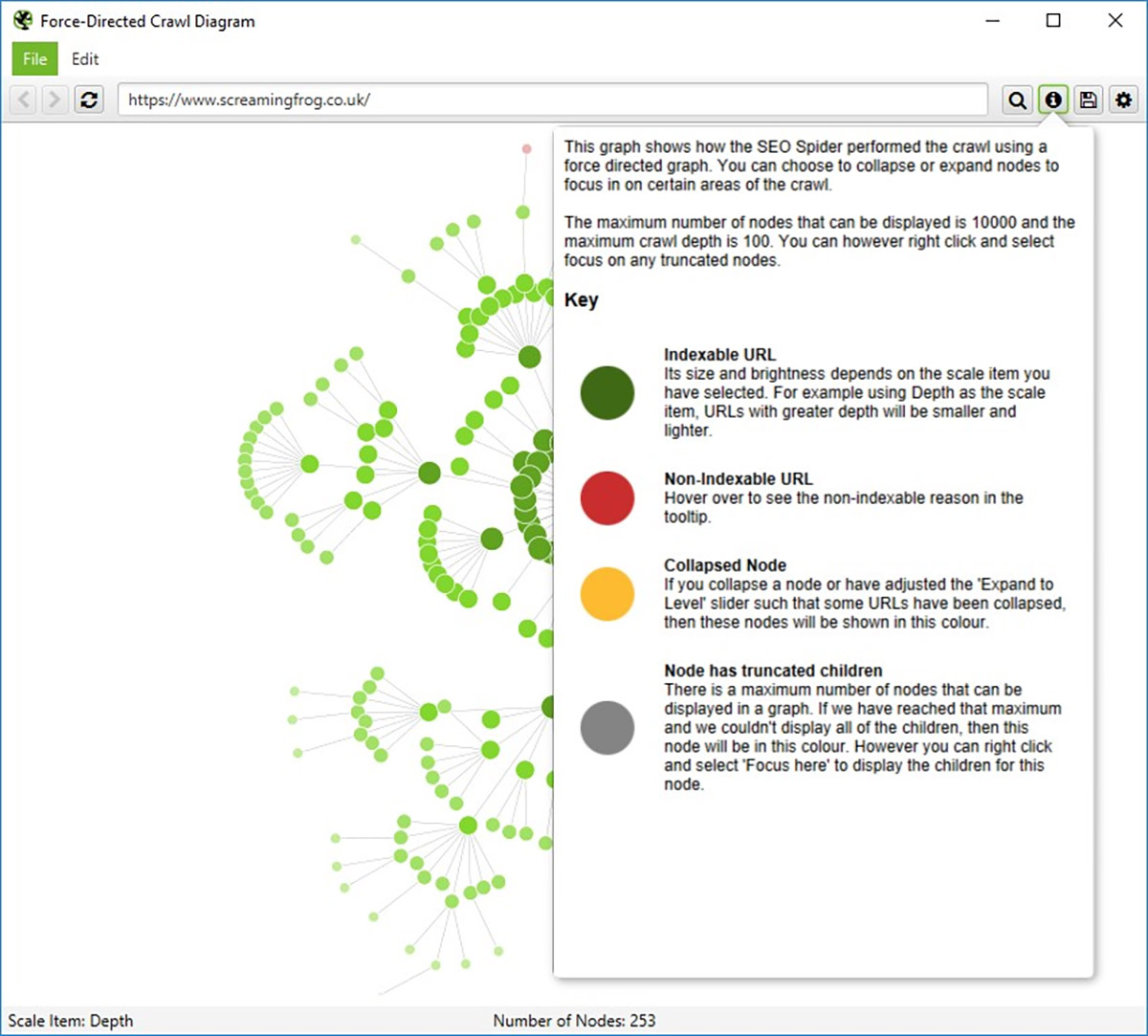
ii. Crawl Analysis
Tính năng Crawl Analytics trong Screaming Frog cung cấp các công cụ và báo cáo để phân tích dữ liệu từ quá trình quét trang web. Đây là một số điểm nổi bật của tính năng này:
- Data Export: Cho phép xuất dữ liệu từ quá trình quét dưới dạng tệp CSV hoặc Excel. Điều này giúp bạn dễ dàng xử lý và phân tích dữ liệu ngoài Screaming Frog, hoặc chia sẻ dữ liệu với các đồng nghiệp hoặc khách hàng.
- Custom Reports: Bạn có thể tạo các báo cáo tùy chỉnh dựa trên các tiêu chí cụ thể, như lỗi trang, các trang bị thiếu thẻ meta, hoặc các vấn đề về cấu trúc URL.
- Charts and Graphs: Cung cấp đồ thị và biểu đồ để trực quan hóa dữ liệu. Điều này giúp bạn nhanh chóng nhận diện các vấn đề hoặc xu hướng, chẳng hạn như tỷ lệ phần trăm của các lỗi HTTP, tỷ lệ các loại thẻ meta, hoặc phân bố của các thẻ tiêu đề.
- Aggregation and Filtering: Cho phép bạn tổng hợp và lọc dữ liệu theo các tiêu chí như lỗi trang, mã trạng thái HTTP, hoặc các thuộc tính HTML cụ thể. Điều này giúp bạn dễ dàng tập trung vào các vấn đề quan trọng và quản lý dữ liệu hiệu quả hơn.
- Integration with Google Analytics: Nếu bạn kết nối với Google Analytics, bạn có thể kết hợp dữ liệu quét với dữ liệu phân tích web để có cái nhìn sâu hơn về hiệu suất trang web và hành vi của người dùng.
Tham khảo: Crawl Analysis Guide – Screaming Frog SEO Spider
iii. So sánh các lần quét dữ liệu
Tính năng Crawl Comparison trong Screaming Frog cho phép bạn so sánh kết quả của các lần quét trang web khác nhau. Đây là một công cụ rất hữu ích để theo dõi sự thay đổi trên trang web theo thời gian và đánh giá hiệu quả của các chiến lược SEO hoặc các thay đổi kỹ thuật.
Dưới đây là một số điểm nổi bật của tính năng Crawl Comparison:
- So Sánh Hai Lần Quét: Bạn có thể so sánh kết quả từ hai lần quét khác nhau để thấy được sự khác biệt về các vấn đề như lỗi 404, mã trạng thái HTTP, các thẻ meta, liên kết nội bộ, và nhiều yếu tố khác.
- Dễ Dàng Nhận Diện Thay Đổi: Tính năng này giúp bạn dễ dàng nhận diện các thay đổi giữa các lần quét, chẳng hạn như các trang mới, các trang bị xóa, hoặc các thay đổi trong cấu trúc liên kết.
- Báo Cáo Chi Tiết: Screaming Frog cung cấp các báo cáo chi tiết về sự khác biệt giữa các lần quét, giúp bạn hiểu rõ hơn về các vấn đề đã được khắc phục hoặc mới phát sinh.
- Phân Tích Xu Hướng: Bạn có thể theo dõi xu hướng và sự tiến triển của trang web theo thời gian, chẳng hạn như cải thiện tốc độ tải trang hoặc giảm số lượng lỗi 404.
- Dễ Dàng So Sánh: Tính năng cho phép so sánh dữ liệu theo các chỉ số cụ thể, như số lượng liên kết nội bộ hoặc các vấn đề SEO, giúp bạn có cái nhìn tổng quan về hiệu quả của các thay đổi trên trang web.

Tham khảo: https://www.screamingfrog.co.uk/seo-spider/tutorials/how-to-compare-crawls/
3.3. Xuất dữ liệu
Ở vùng I và vùng II trong Screaming Frog đều có ô Export để bạn xuất dữ liệu.
3.3.1 Xuất dữ liệu ở từng vùng
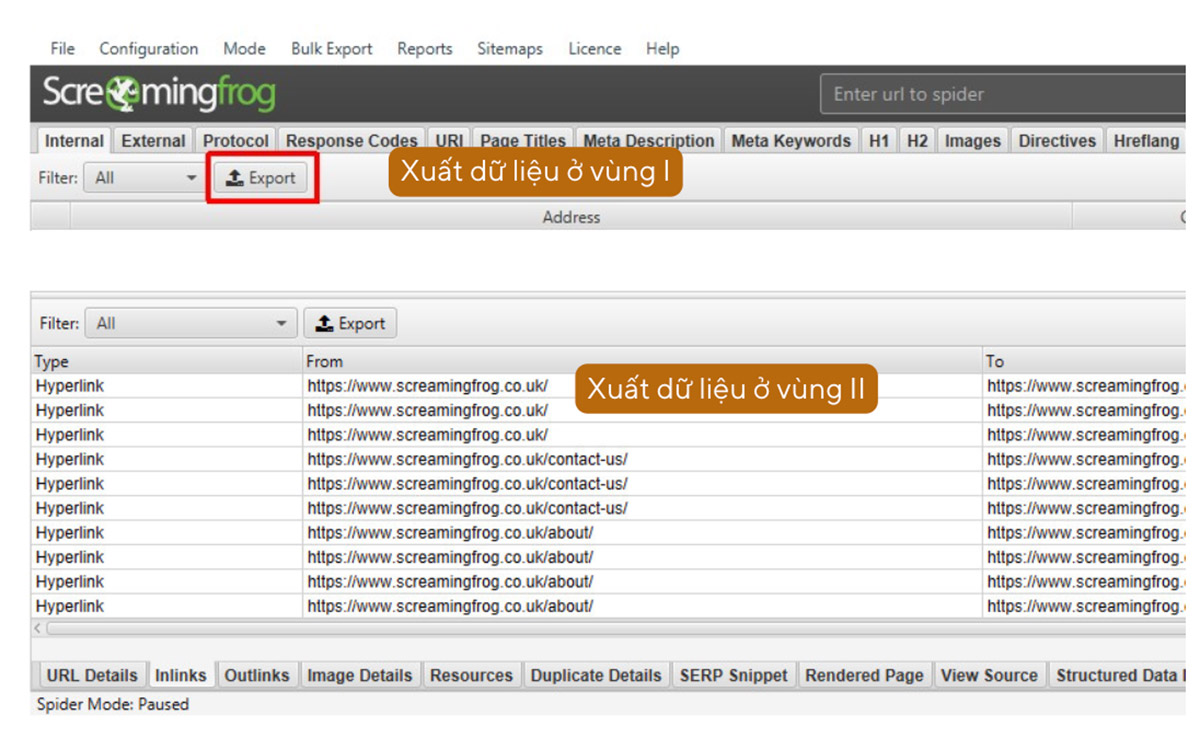
3.3.2 Xuất dữ liệu ở nhiều vùng
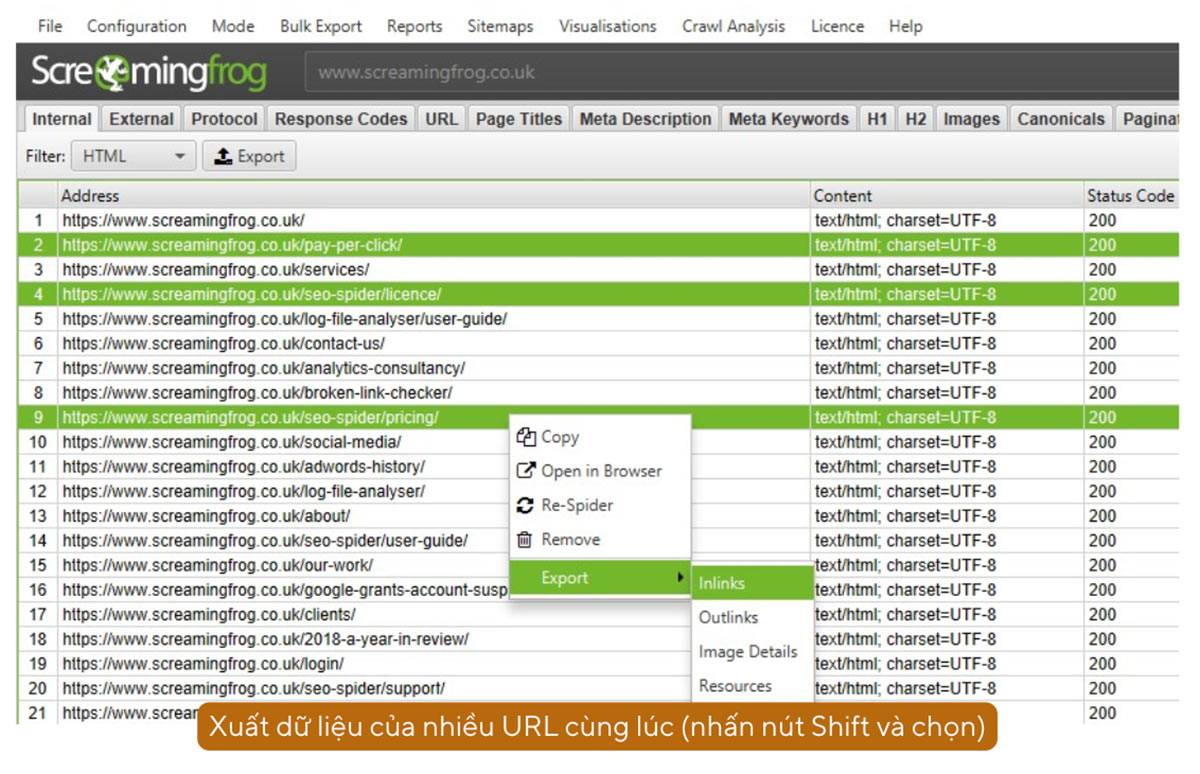
Ngoài ra, bạn có thể xuất dữ liệu của nhiều URL trên vùng I cùng lúc bằng cách nhấn giữ nút Shift và chọn các URL.
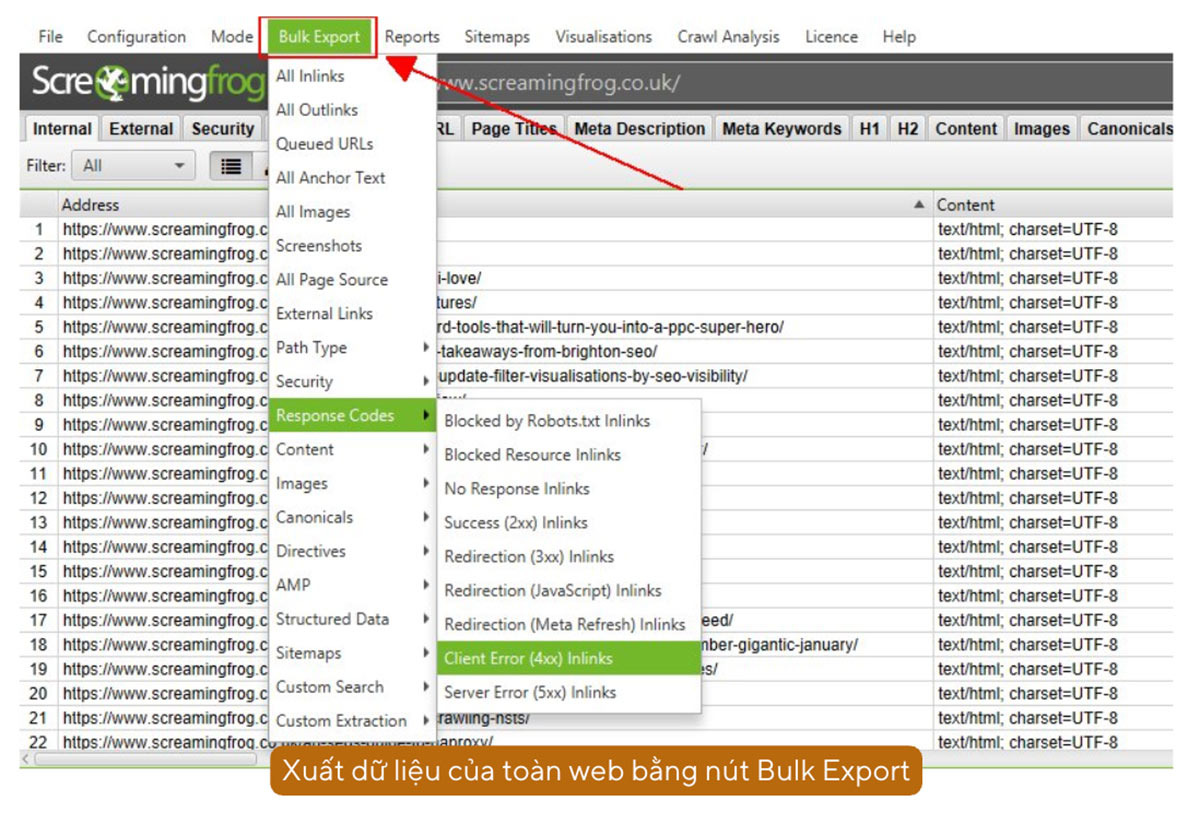
Bạn cũng có thể xuất dữ liệu toàn trang bằng cách sử dụng nút Bulk Export.
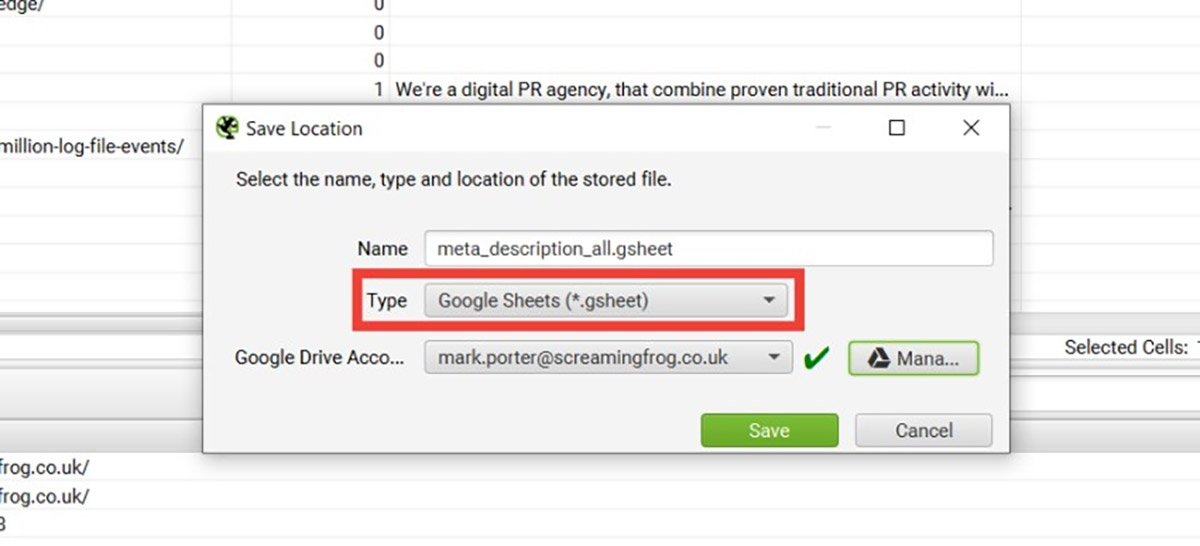
3.3.3. Xuất dữ liệu vào Google sheet
Screaming Frog cho phép bạn xuất dữ liệu đã thu thập được vào nhiều định dạng khác nhau để phân tích và báo cáo. Dưới đây là một số tùy chọn xuất dữ liệu:
- CSV (Comma-Separated Values): Xuất dữ liệu thành file CSV, dễ dàng mở bằng các chương trình như Microsoft Excel hoặc Google Sheets.
- Excel: Xuất dữ liệu trực tiếp thành file Excel (.xlsx).
- Google Sheets: Kết nối trực tiếp và xuất dữ liệu vào Google Sheets.
- Database: Xuất dữ liệu vào cơ sở dữ liệu như MySQL hoặc SQL Server.
- JSON: Xuất dữ liệu thành định dạng JSON để sử dụng trong các ứng dụng web hoặc lập trình.
4. Ứng dụng Screaming Frog vào quy trình SEO PPP của SEONGON
4.1. Check bài đăng của CTV
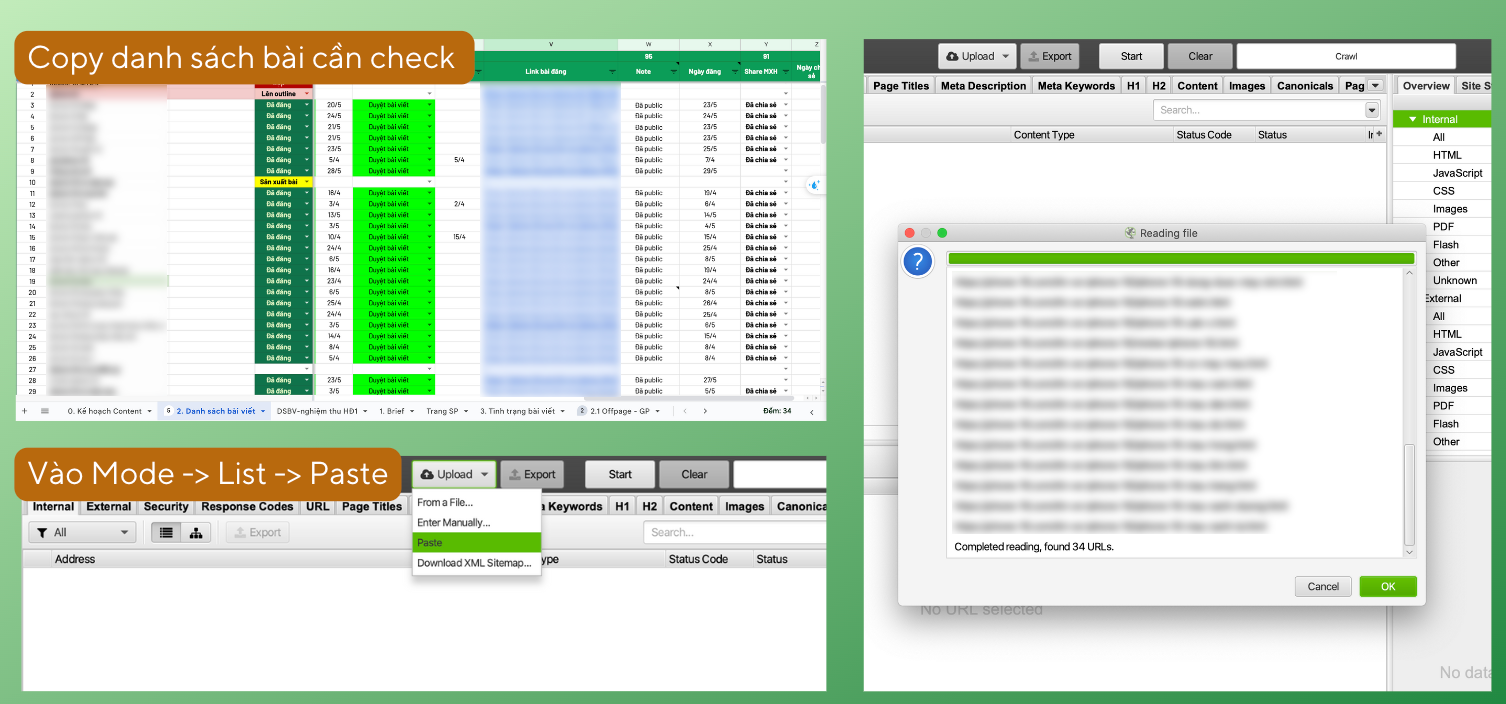
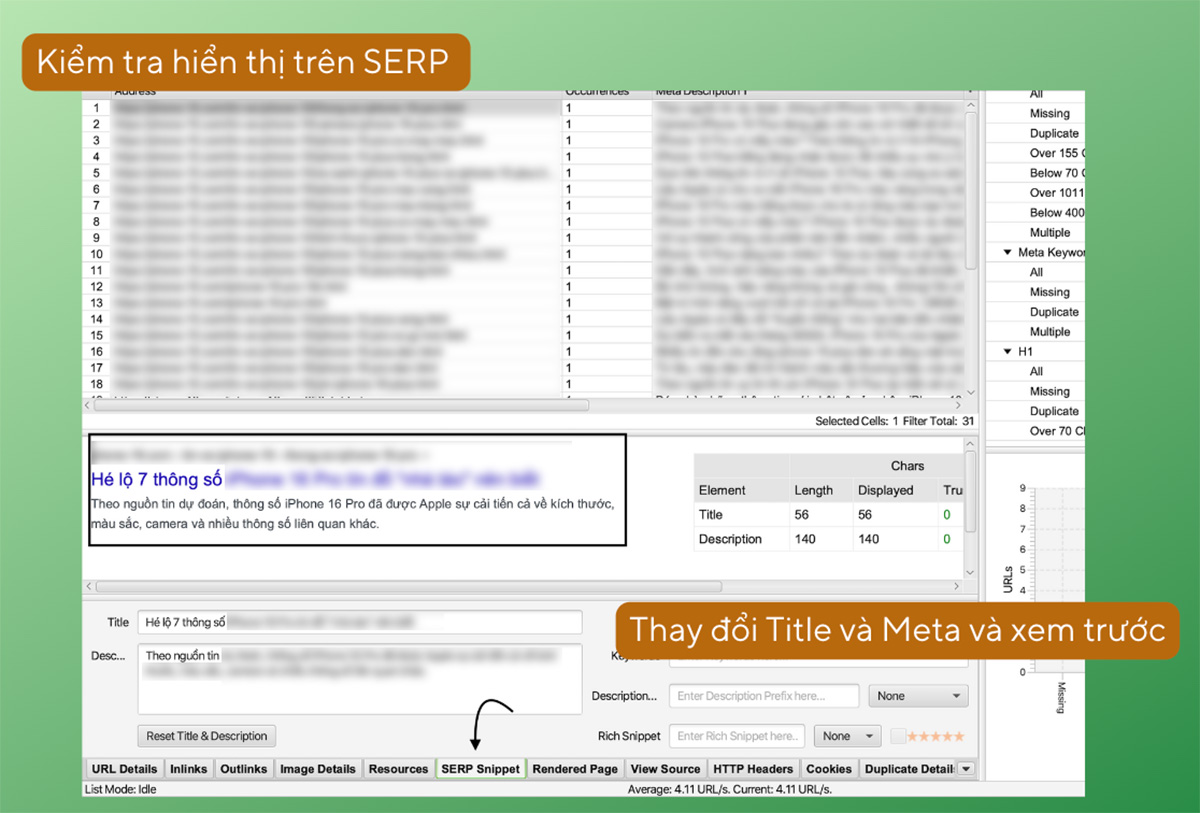
Screaming Frog sẽ nhanh chóng cho bạn biết các thông tin cần check như Title, Meta, H1, v.v. Bạn có thể xem được các Meta đang bị quá dài, hay các trang bị thiếu Meta, H1, v.v.
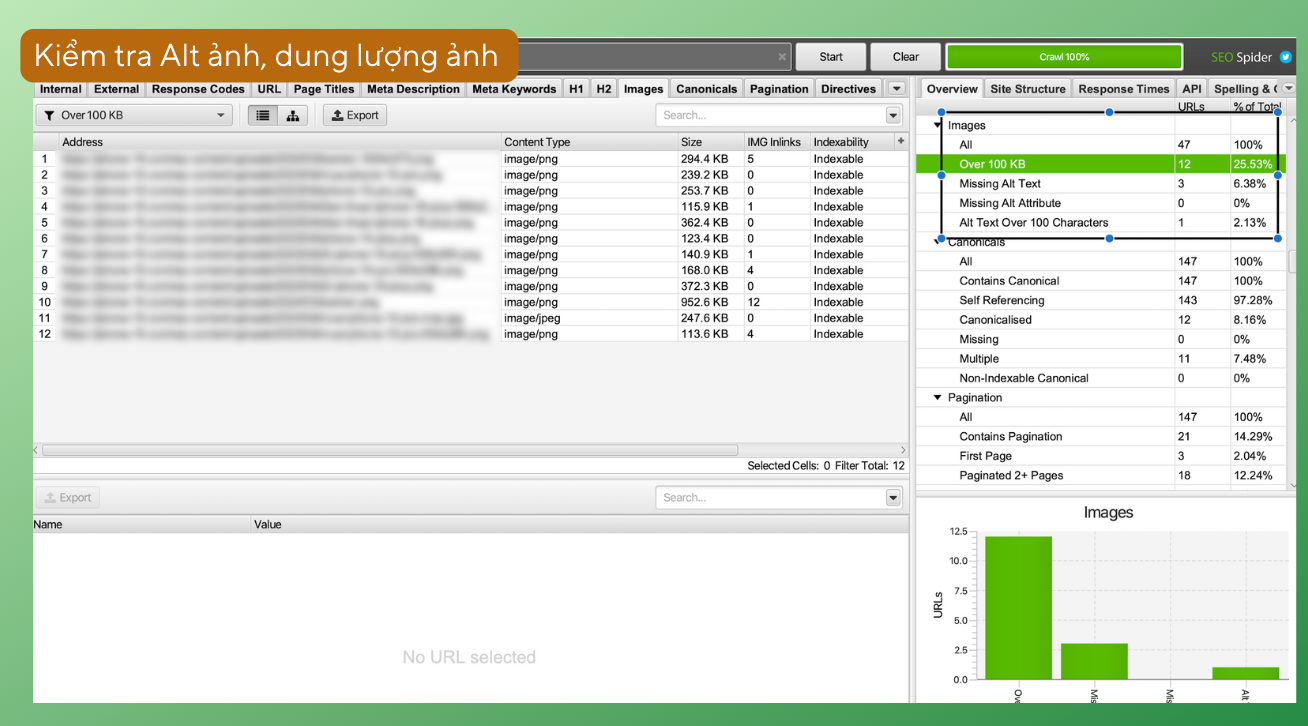
Ngoài ra, bạn có thể vào tab Images để xem các ảnh đang có dung lượng lớn hơn 100kb, thiếu Alt ảnh hay Alt ảnh dài hơn 100 ký tự.
4.2. Schema
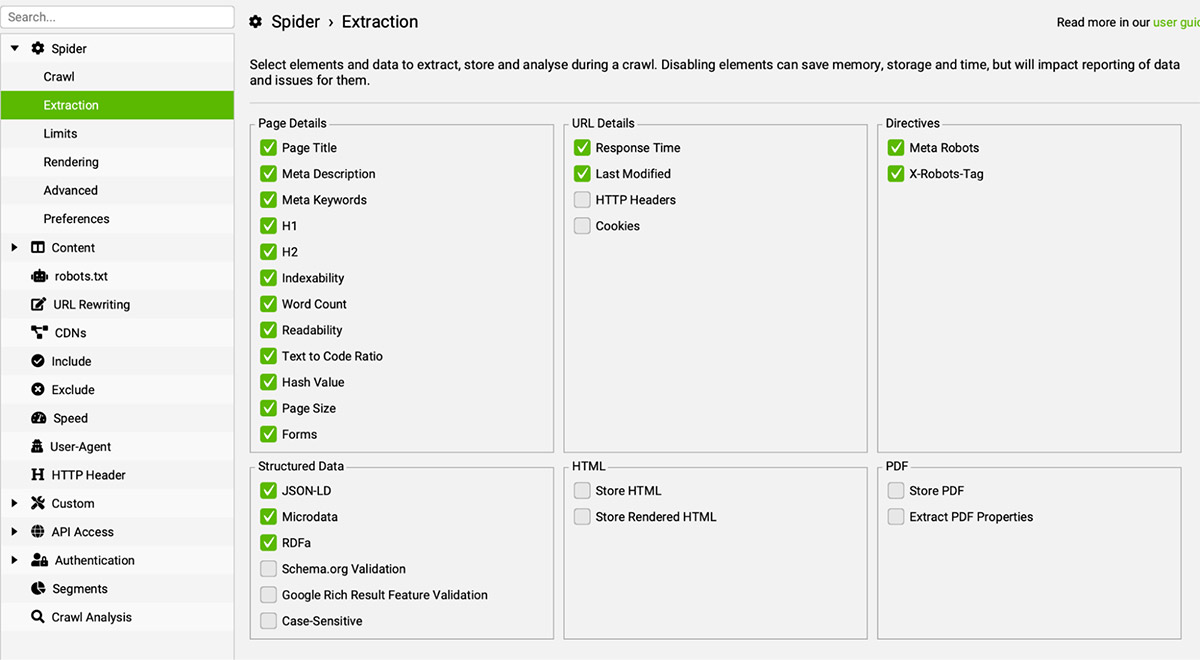
Để cào được dữ liệu Schema, mọi người cần vào Configure -> Structured Data -> Tick chọn tất cả 3 dạng Schema và chọn thêm Google Rich-Result để xem Google đang nhận định các Schema này như thế nào.
Vào tab Structured Data để xem từng loại và lỗi.
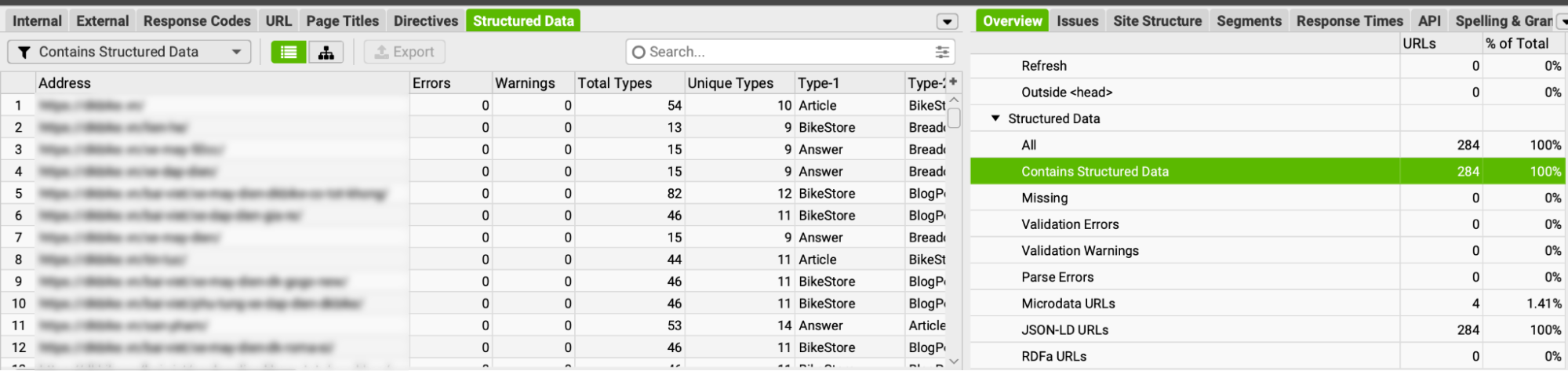
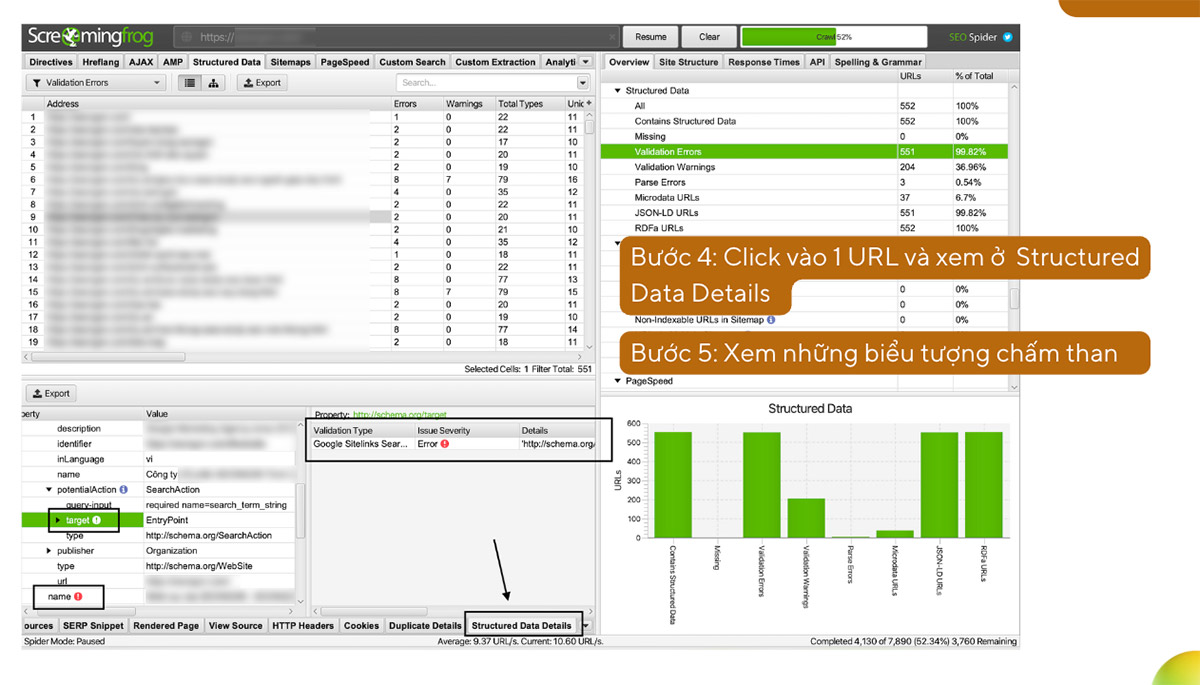
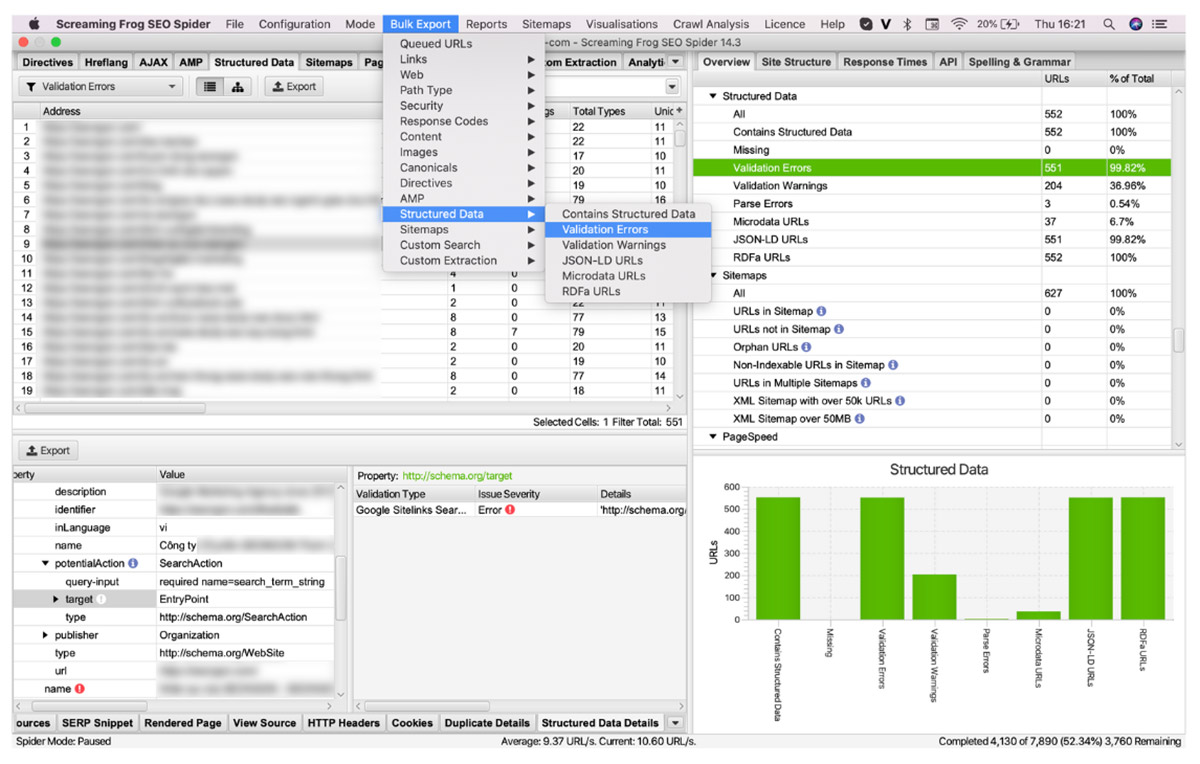
Bạn có thể xuất các dữ liệu của Schema ra bằng cách sử dụng Bulk Export.
4.3. Audit Internal Link
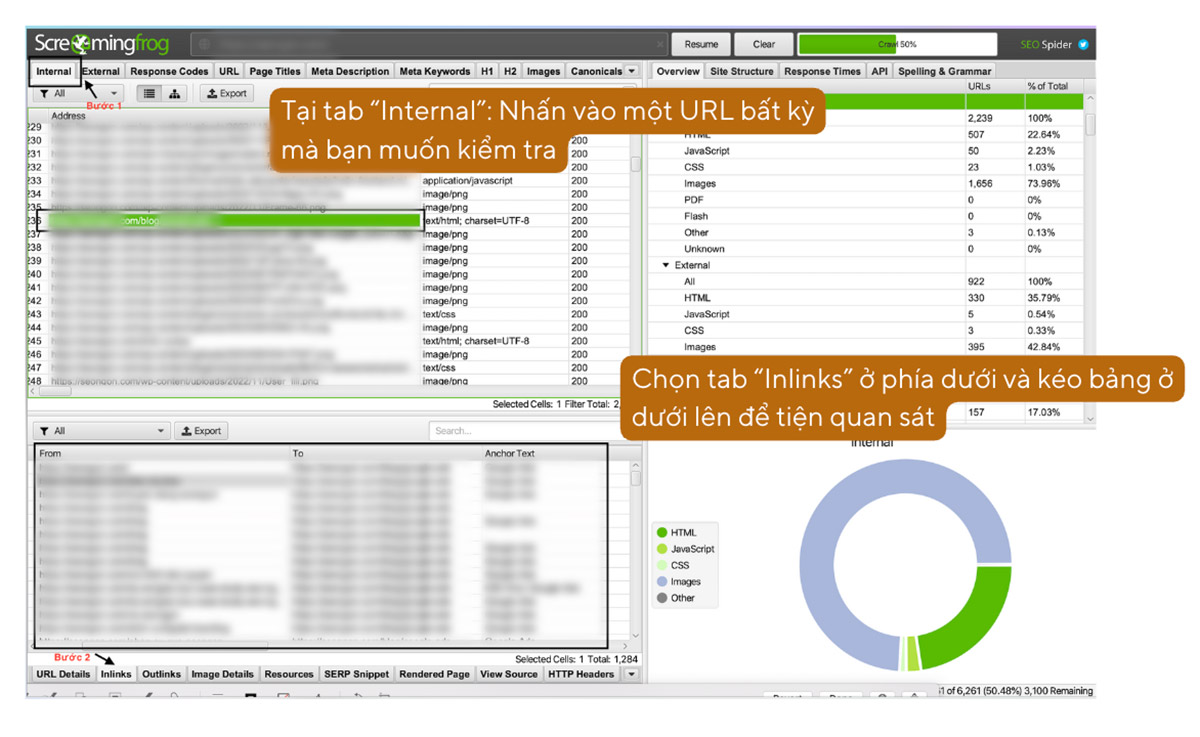
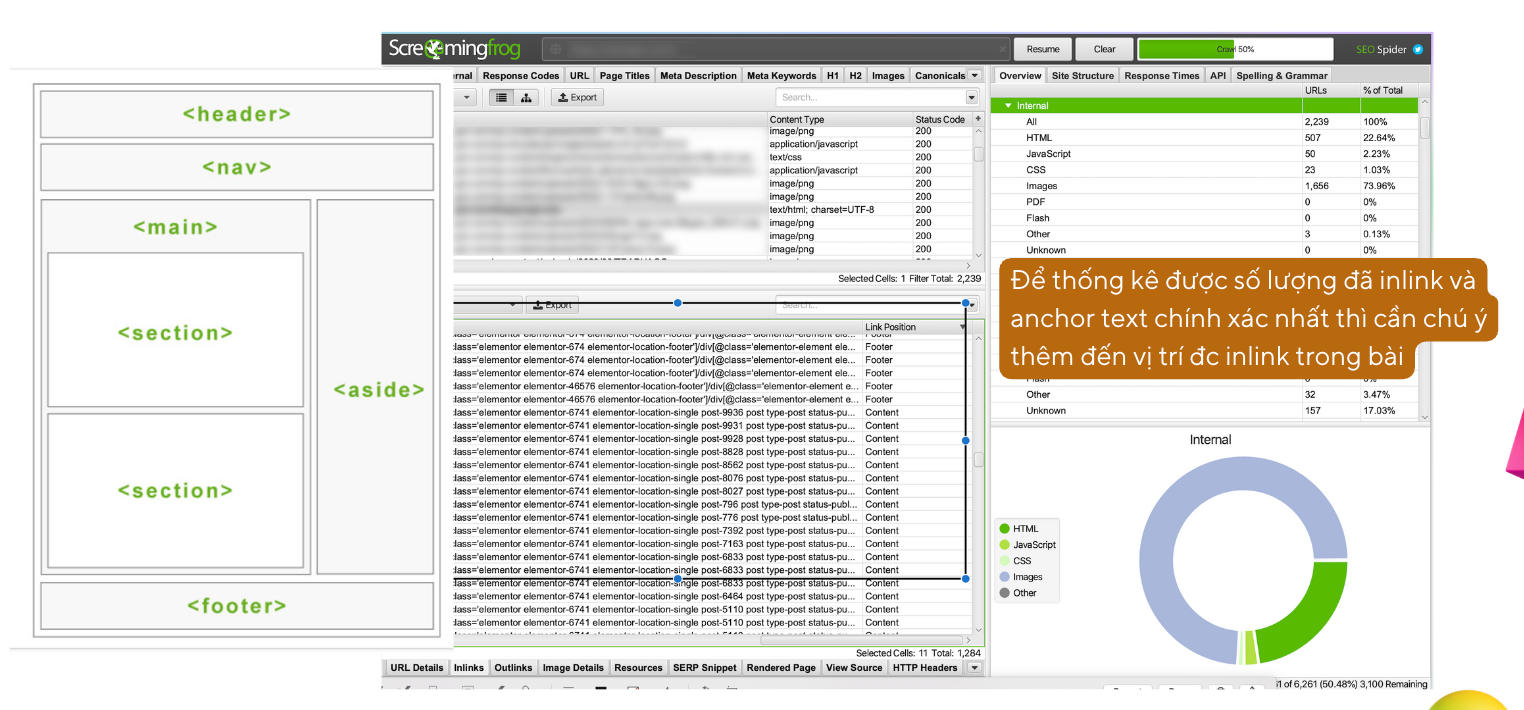
Bạn có thể xuất toàn bộ Internal Link, Anchor Text của website bằng cách sử dụng Bulk Export.
4.4. Check backlink
Sau khi đi Offpage, bạn có thể check lại tình trạng Index và Anchor Text của Offpage bằng cách sử dụng Screaming Frog.
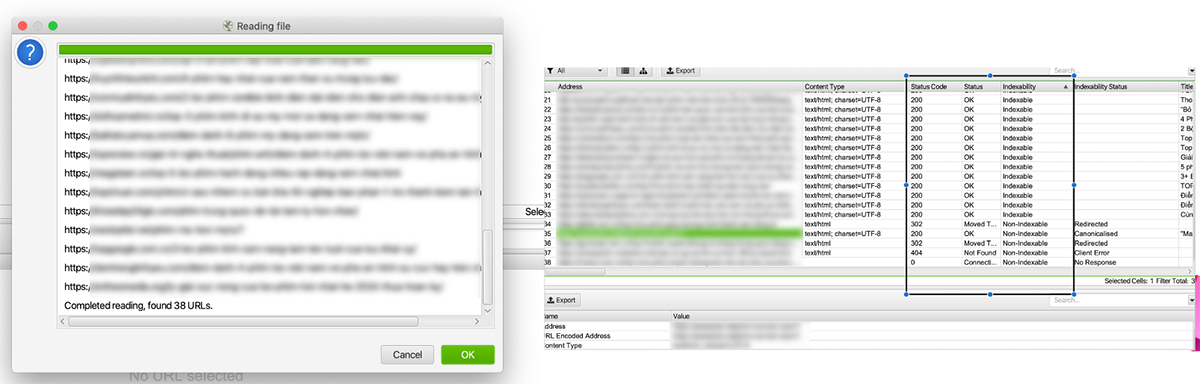
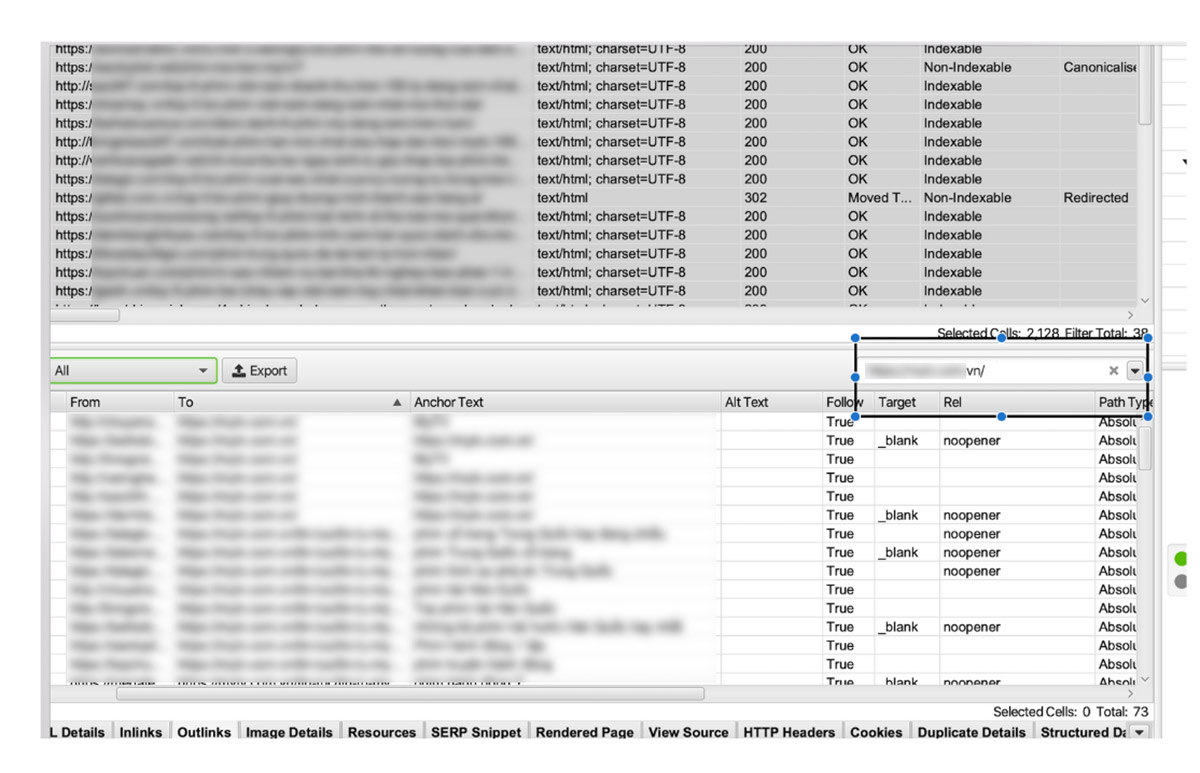
4.5. Custom Extraction
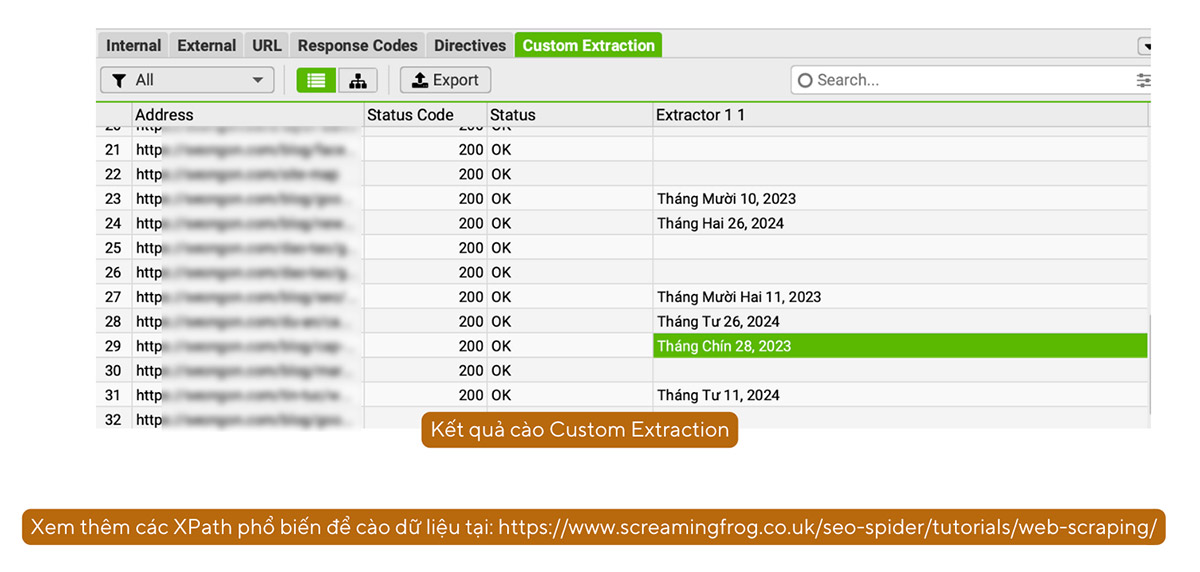
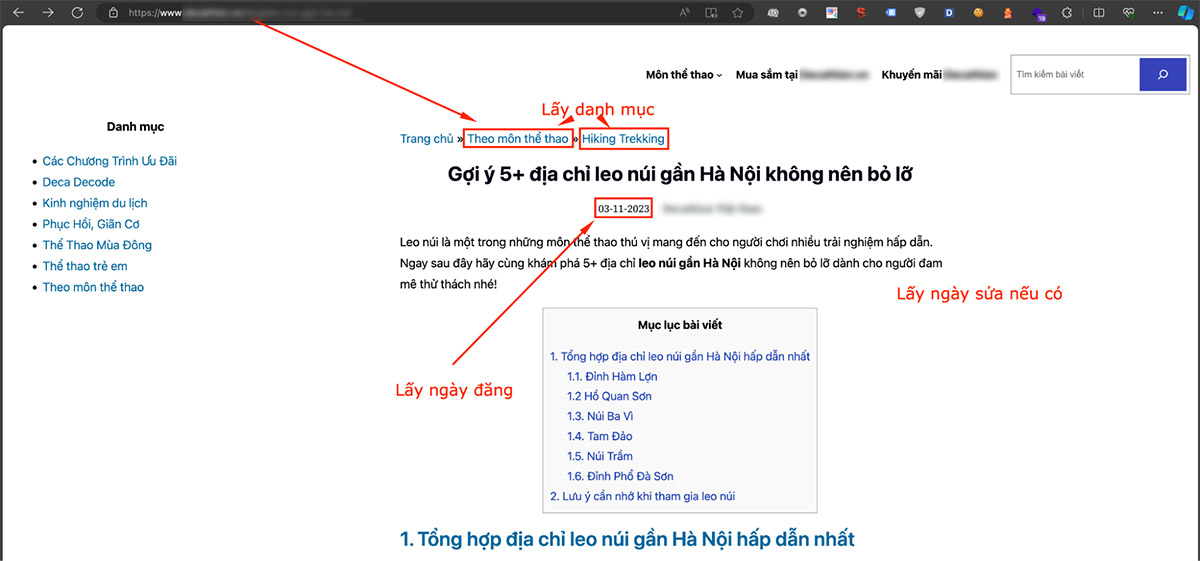
4.5.1. Quét ngày đăng của từng bài
4.5.2. Quét số sản phẩm trong mỗi danh mục
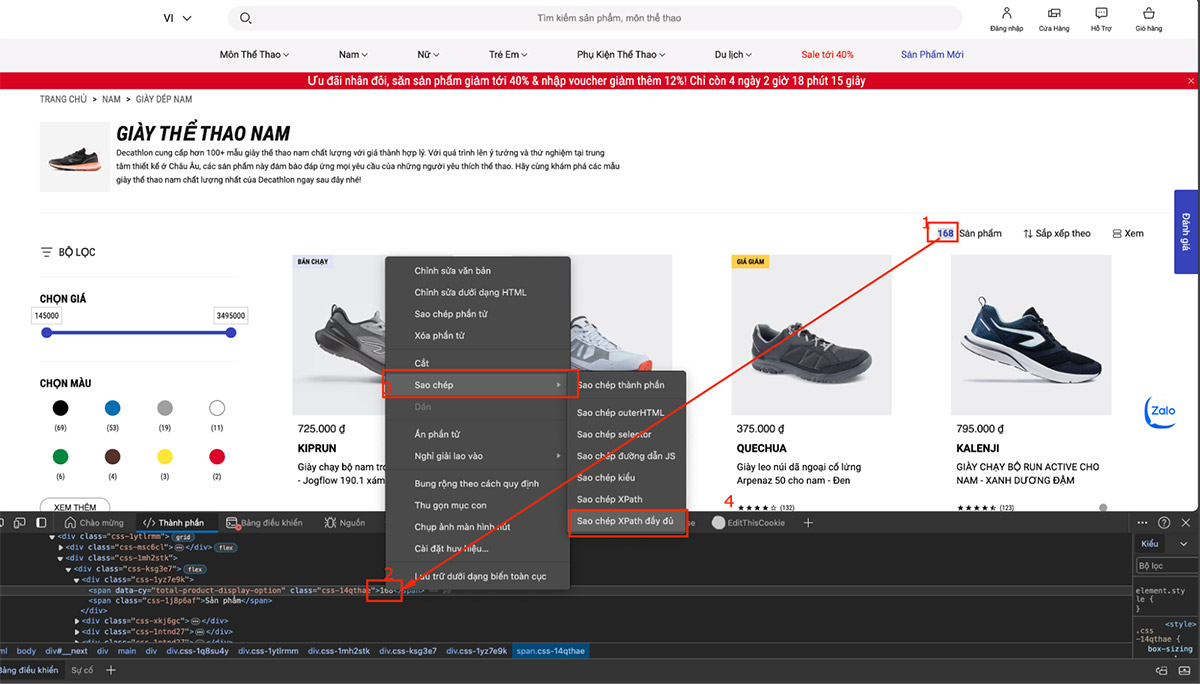
4.5.3. Lấy danh mục của bài viết
———
Nếu bạn đang gặp vấn đề về SEO Website mà vẫn chưa tìm ra được giải pháp, dịch vụ SEO tổng thể của SEONGON là dành cho bạn. SEONGON không chỉ giải quyết những vấn đề website đang bị hạn chế, mà còn tối ưu trang web hiệu quả để tăng trải nghiệm người dùng. Để được hỗ trợ nhanh nhất về dịch vụ SEO tổng thể, bạn có thể gửi email đến contact@seongon.com hoặc gọi điện 090 1707 090 (nhánh 1).